在您的网站上添加自己的 AI 助手,无需企业级成本
像 AI 聊天机器人这样的自定义 RAG 解决方案不必花费昂贵。您可以使用 Cloudflare 慷慨的免费套餐免费运行它们。
像 AWS Kendra 或 Azure AI Search 这样的企业级平台每月可能花费数千美元,而像 Pinecone 的入门级套餐或使用 pgvector 的自托管解决方案则提供了更经济的选择。在参与了多个 RAG 项目之后,我发现 Cloudflare AI Search 根据您的需求可能是一个不错的选择。它不适用于所有用例,但在许多场景下,它能处理大部分繁重的工作。
本文将介绍我如何使用 Cloudflare AI Search 为本网站构建一个聊天机器人。我将涵盖什么是 RAG、AI Search 如何简化管道、实施细节(流式传输、存储、速率限制)、实际成本以及如何将其扩展到商业用例。
虽然这是一个个人网站(我的数字花园),但相同的架构适用于您索引个人网站还是公司文档。
什么是 RAG?
RAG(检索增强生成)是一种将 LLM 的响应以您的实际数据为基础的模式。RAG 不仅仅依赖模型的训练数据,它还会从您的文档中检索相关内容并将其包含在提示中。
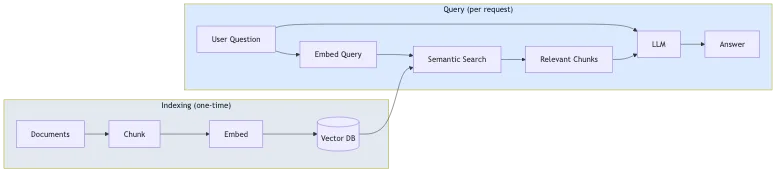
该过程有两个阶段:
- 索引(一次性):您的文档被分割成块,转换为向量嵌入,并存储在向量数据库中
- 查询(每次请求):用户的提问被嵌入,通过语义搜索检索相似的块,然后 LLM 使用这些块作为上下文生成答案
这种方法减少了幻觉,因为模型是根据您的内容而不是仅仅根据其一般知识来回答的。这也意味着您不需要在内容更改时重新微调模型。
Cloudflare AI Search 实际做了什么
在深入研究实现细节之前,值得了解一下 AI Search(以前称为 AutoRAG)开箱即用提供了什么:
- 自动索引:指向您的网站或数据源,它会自动抓取和索引您的内容
- 向量嵌入:它生成并管理用于语义搜索的嵌入
- RAG 管道:它检索相关内容并使用该上下文生成响应
- 持续更新:当您的内容更改时,索引会自动更新
这意味着您不需要自己构建分块、嵌入、向量存储或检索逻辑。AI Search 负责所有这些。
架构概述
这是我实际构建的内容:
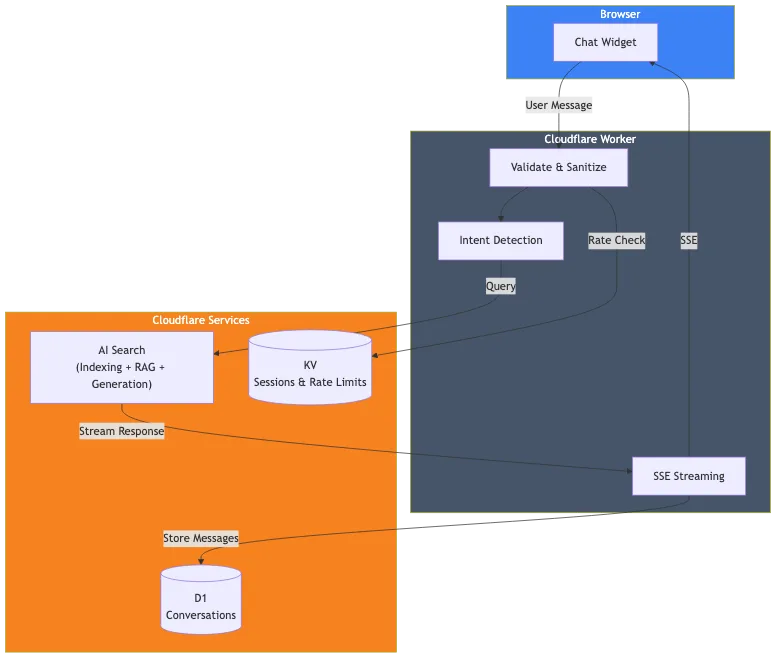
组件包括:
- Cloudflare AI Search:索引本网站并处理 RAG 管道
- Cloudflare Worker:处理请求、验证和流式传输响应
- Cloudflare D1:存储对话历史记录以供分析
- Cloudflare KV:管理会话和速率限制
核心实现
实际的 AI Search 调用很简单。这是关键部分:
// 从 Cloudflare 上下文中获取 AI 绑定
const ai = await getCloudflareAI();
// 调用 AI Search
const aiSearch = ai.autorag('your-ai-search-instance');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});RAG 部分就到此为止。AI Search 接收用户的查询,搜索我索引的网站内容,检索相关块,并使用该上下文生成响应。
设置 AI Search
要使用 AI Search,您需要:
- 在 Cloudflare 控制台中创建一个 AI Search 实例
- 连接您的数据源(在我的例子中是本网站)
- 等待初始索引完成
- 将 AI 绑定添加到您的 wrangler.toml
# wrangler.toml
[ai]
binding = "AI"配置完成后,AI Search 会持续监控您的数据源并在内容更改时更新索引。
系统提示
系统提示定义了 AI 应如何表现。这是您塑造聊天机器人个性和边界的地方:
function getSystemPrompt(locale: string): string {
return `You are a helpful AI assistant on David Loor's portfolio website.
## CRITICAL RULES:
1. ALWAYS respond in ${languageNames[locale]}
2. ONLY answer questions about David Loor - you are NOT a general-purpose assistant
3. Use the provided context about David - do not make up information
## Your Behavior:
- Be helpful and professional
- Keep responses concise (2-3 paragraphs max)
- When appropriate, mention they can book a call or send an email
- Don't discuss pricing - suggest they discuss directly
- Don't pretend to be David - you're his AI assistant`;
}关键规则部分很重要。如果没有明确的界限,聊天机器人会尝试回答一般知识问题,这正是我不希望作品集助手做的事情。
流式传输响应
没有人想在看到任何内容之前等待完整的响应。AI Search 通过 stream: true 开箱即用地支持流式传输。您可以使用 Server-Sent Events (SSE) 将响应直接传输给客户端,为用户提供那种熟悉的 ChatGPT 式的打字效果。
使用 D1 存储对话
如果您想分析对话或随着时间的推移改进您的聊天机器人,您可以将它们存储在 Cloudflare D1(他们的无服务器 SQLite)中。只需在后台运行数据库写入操作,以免阻塞流式响应。
使用 KV 进行速率限制
公共 API 需要保护。我使用 Cloudflare KV 进行简单的速率限制:
const RATE_LIMIT_WINDOW_MS = 60000; // 1 minute
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 messages per minute
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// New window
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Rate limited
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}本地开发
对于本地开发,我使用 npx wrangler dev,它在本地运行 Worker,同时连接到我的生产 Cloudflare 服务(AI Search、D1、KV)。这使我能够在部署之前获得类似生产环境的测试环境:
npx wrangler devWorker 代码在我的机器上运行,但绑定连接到真实的远程服务。这意味着本地开发确实会消耗您的神经元配额,但这是部署前进行测试的最准确方式。
这项服务花费了我多少
好消息是:您可以在 Cloudflare 的免费套餐上运行整个堆栈。无需付费套餐。
| 服务 | 免费套餐限制 |
|---|---|
| AI Search | 所有套餐(包括免费)均可用 |
| Workers AI | 每天 10,000 个神经元 |
| D1 | 每天 500 万次读取,每天 10 万次写入,5GB 存储 |
| KV | 每天 10 万次读取,每天 1K 次写入,1GB 存储 |
| Workers | 每天 10 万次请求 |
您首先会遇到的主要限制是 Workers AI 神经元。我们来算一下。
Workers AI(主要成本)
您每天免费获得 10,000 个神经元(每月约 300,000 个)。与 AI Search 的典型聊天交互根据响应长度大约使用 500-1,000 个神经元。这意味着:
- 每天约 300-600 条聊天消息后超出免费套餐
- 每月约 9,000-18,000 条消息包含在内
对于大多数个人网站和小企业来说,这足以完全免费运行。超出此范围,每 1,000 个神经元收费 0.011 美元。一个繁忙的聊天机器人如果每天处理 1,000 条消息,每月额外花费约 5-10 美元。
其他服务(慷慨的限制)
其他免费套餐限制非常慷慨:
- Workers 请求:每天 10 万次。这相当于每天约 10 万条聊天消息才达到限制。
- D1 读取:每天 500 万次。每次聊天会消耗几次读取,因此每天可支持数千次聊天。
- D1 写入:每天 10 万次。每条消息存储 2 行,因此每天可支持约 5 万条消息。
- KV 读取:每天 10 万次。速率限制每条消息消耗约 2 次读取。
对于大多数网站来说,Workers AI 神经元是您真正会接近的唯一限制。其他服务的每日限制会重置,为您提供充足的余量。
我没有构建什么
值得注意的是 AI Search 为我处理了哪些工作:
- 文档分块:我没有编写任何分块逻辑
- 嵌入生成:AI Search 生成并管理嵌入
- 向量存储:无需单独设置 Vectorize
- 检索逻辑:AI Search 处理语义搜索
- 索引更新:内容更改会自动被拾取
如果我使用单独的嵌入、向量数据库和检索管道从头开始构建它,那将是更多的工作。AI Search 抽象了所有这些。
将此扩展到商业用例
虽然我是为我的个人网站构建此功能的,但相同的模式也适用于商业场景。AI Search 支持除网站之外的其他数据源:
客户支持
将 AI Search 指向您的文档网站、帮助中心或知识库。聊天机器人可以回答产品问题、故障排除查询和政策问题,而无需训练自定义模型。根据需要添加逻辑以升级到人工座席。
内部知识助手
索引您的公司维基、Confluence 或内部文档。员工可以用自然语言提问,而不是在文件夹中搜索。系统提示定义了访问边界和响应风格。
电子商务产品顾问
索引您的产品目录页面。客户可以问“1000 美元以下有什么适合视频编辑的笔记本电脑?”并获得基于您实际库存的答案。将准备购买的客户引导至结账页面。
规模化时会发生什么变化
核心架构保持不变。变化的是:
- 数据源:不再是个人网站,而是连接您的业务内容
- 系统提示:根据您的品牌声音和用例量身定制
- 业务逻辑:基于用户需求的自定义路由
- 速率限制:根据预期流量进行调整
- 身份验证:如果索引私有内容,则添加用户身份验证
无论您是索引 50 个页面还是 50,000 个页面,AI Search 都能处理 RAG 的复杂性。
模型灵活性
AI Search 不局限于单一模型。您有多种选择:
生成模型: AI Search 支持来自多个提供商的模型,包括 Anthropic (Claude 3.5, Claude 4)、Google (Gemini 2.5 Flash/Pro)、OpenAI (GPT-4o, GPT-5),以及 Cerebras、Grok、Groq 和 Workers AI。您可以选择 Cloudflare 会自动更新的智能默认设置,或者 选择特定模型。甚至可以通过 API 为每次请求覆盖生成模型。
嵌入模型: 选项包括 OpenAI 的 text-embedding-3 模型、Google 的 Gemini Embedding 以及 Workers AI 的 BGE 模型。嵌入模型在初始设置期间设置,之后无法更改(这将需要重新索引所有内容)。
自带模型: 如果支持的模型不符合您的需求,您可以通过 AI Gateway 自带生成模型,或者仅将 AI Search 用于检索并将结果发送到任何外部 LLM。
局限性
这种方法有一些限制:
- Cloudflare 特有:AI Search 仅在 Cloudflare 的生态系统内工作
- 检索调整有限:您可以调整 块大小和重叠,但无法调整底层分块策略或检索算法
- 数据源有限:AI Search 支持 网站和 R2 存储(用于 PDF、文档等),但不能直接用于任意数据库或 API
对于更复杂的用例(自定义分块、多个异构数据源或专业检索),您需要使用 Vectorize 和 Workers AI 直接构建更多的管道。
请尝试页面角落的聊天机器人。它运行的正是此处描述的内容。
如果您正在构建类似的东西并想讨论细节,让我们聊聊。