我选择使用 Server-Sent Events 而非 WebSockets 来流式传输 AI 响应的原因
当我构建 Kindle-ChatGPT 时,我需要在客户端实时流式传输 AI 响应。你知道那种看着 ChatGPT 一个词一个词地打出其响应的令人满足的体验吗?我想要那种感觉。
我的第一反应是使用 WebSockets。它是实时通信的首选解决方案,对吧?但在做了一些研究之后,我意识到一个更简单、更优雅的解决方案就隐藏在眼前:服务器发送事件(Server-Sent Events,简称 SSE)。
什么是服务器发送事件?
Server-Sent Events 是一种标准,它允许服务器通过单个 HTTP 连接向客户端推送数据。与 WebSockets 不同,SSE 是单向的:服务器向客户端发送数据,但客户端不能反向发送数据。
该协议非常简单。服务器以 Content-Type: text/event-stream 响应,并以以下格式发送数据:
data: Hello
data: World
data: {"message": "JSON 也有效"}
每条消息都以 data: 为前缀,并用两个换行符分隔。就是这样。没有握手,没有帧解析,没有连接升级。
为什么选择 SSE 而不是 WebSockets?
关于流式传输 AI 响应,情况是这样的:客户端发送一个问题,服务器流式传输答案回来。这本质上是单向流动。我为什么要建立双向通信,而我只需要数据单向流动呢?
WebSockets 可以工作,但它们会带来开销:
- 连接升级:WebSockets 需要一个 HTTP 升级握手
- 持久连接管理:你需要处理重连逻辑、心跳和连接状态
- 基础设施复杂性:一些代理和 CDN 对 WebSockets 的支持不佳
- 更多代码:客户端和服务器都需要更复杂的实现
另一方面,SSE:
- 使用标准 HTTP:可以通过任何处理 HTTP 的代理、CDN 或负载均衡器工作
- 内置重连:浏览器的
EventSourceAPI 会自动重连 - 简单协议:只是通过 HTTP 传输文本
- 原生浏览器支持:客户端无需库
对于我用例——从 AI 模型流式传输文本——SSE 是显而易见的选择。
Gemini API 如何使用 SSE
我一开始没有意识到这一点:Google 的 Gemini API 原生支持 SSE 来流式传输响应。你只需在端点后添加 ?alt=sse:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
API 返回一个事件流,每个事件包含响应的一个块:
data: {"candidates":[{"content":{"parts":[{"text":"Hello"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" there"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":"!"}],"role":"model"}}]}
使用 TransformStream 构建流式代理
我的服务器充当客户端和 Gemini 之间的代理。但我不想将原始的 Gemini SSE 格式转发给客户端。嵌套的 JSON 结构(candidates[0].content.parts[0].text)对于我简单的聊天界面来说过于复杂了。
相反,我使用了一个 TransformStream 来解析 SSE 事件并仅提取文本:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // 将不完整的行保留在缓冲区中
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// 优雅地处理解析错误
}
}
}
},
flush(controller) {
// 处理缓冲区中任何剩余的数据
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// 处理最终解析错误
}
}
}
});
这里有一个微妙但重要的细节:SSE 事件可能会在网络块之间分割。一条 data: 行可能以两个部分到达。缓冲区通过将不完整的行保留在缓冲区中,直到下一个块到达来处理这种情况。
客户端实现
在客户端,我可以使用原生的 EventSource API。但由于我的转换流发送的是纯文本(而不是 SSE 格式),我直接使用了 ReadableStream API:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// 使用累积的消息更新 UI
setMessage(fullMessage);
}
这就是流式传输的妙处:每个块都在 AI 生成时到达,我们可以立即更新 UI。
为电子墨水屏优化
这是我的特定用例变得有趣的地方。Kindle 电子墨水屏的刷新率很慢。如果我对每个块都更新 UI,屏幕会不断闪烁,难以跟上。
解决方案是限制更新频率(节流):
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // 每 500 毫秒更新一次
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// 始终用最终内容更新
setMessage(fullMessage);
这会将 UI 更新批处理到 500 毫秒的间隔内,同时仍然以数据到达的速度接收数据。文本在内存中累积,显示屏以电子墨水屏可以处理的速度更新。
错误处理和边缘情况
生产代码需要处理几个边缘情况:
1. 流式传输中的网络错误
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 处理块
}
} catch (error) {
// 发生网络错误
// 显示部分消息 + 错误指示器
setMessage(fullMessage + '\n\n[连接中断]');
}
2. API 返回的格式错误 JSON
TransformStream 的 try-catch 确保一个错误的块不会破坏整个流。我们记录错误并继续处理。
3. 空响应
有时 API 返回的块不包含文本内容。可选链(?.)可以优雅地处理这种情况。
何时使用 SSE 与 WebSockets
在这次经历之后,这是我的心智模型:
在以下情况下使用 SSE:
- 数据主要从服务器流向客户端
- 你需要简单的实现和最少的基础设施
- 自动重连很有价值
- 你正在流式传输文本、日志、通知或事件
在以下情况下使用 WebSockets:
- 你需要双向通信
- 低延迟至关重要(游戏、协作编辑)
- 你正在发送二进制数据
- 你需要从客户端频繁发送消息到服务器
对于 AI 聊天应用程序,SSE 正好合适。用户发送一条消息(常规 POST 请求),AI 流式传输响应回来(SSE)。简单、高效,并且在任何地方都有效。
部署注意事项
我将此部署在 Cloudflare Workers 上,SSE 无需任何特殊配置即可工作。Workers 运行时原生支持流式响应:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
需要注意几点:
- 无缓存:流式响应永远不应被缓存
- Keep-alive:有助于为更长的流保持连接
- Content-Type:我使用了
text/plain,因为我发送的是纯文本,而不是 SSE 格式
完整的数据流
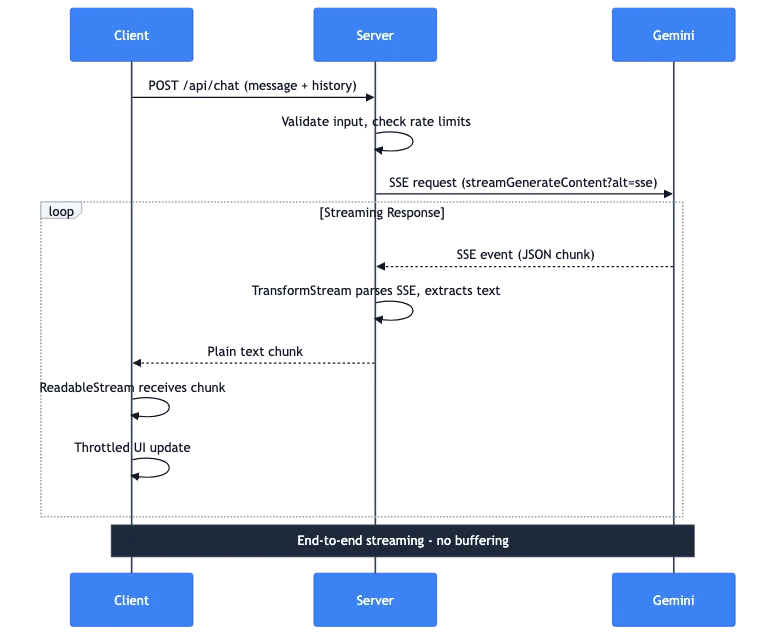
让我来分解一下当用户发送消息时会发生什么:
- 客户端:带有消息和对话历史记录的 POST 请求
- 服务器:验证输入,检查速率限制
- 服务器:向 Gemini API 发起 SSE 请求
- Gemini:流式传输带有 JSON 块的 SSE 事件
- 服务器:TransformStream 解析 SSE,提取文本
- 服务器:将纯文本块转发给客户端
- 客户端:ReadableStream 接收块
- 客户端:限制更新显示文本
整个管道是端到端流式的。服务器上没有缓冲完整的响应。来自 Gemini 的第一个 token 在几毫秒内就能到达用户的屏幕。