Wie man Open-Source-LLMs (KI) auf Ihrem Computer ausführt
Ich habe meinen eigenen KI-Assistenten eingerichtet, der komplett auf meinem Computer läuft. Keine Internetverbindung erforderlich. Keine Daten werden in die Cloud gesendet.
Wenn Sie neugierig darauf waren, Ihre eigene KI auszuführen, aber dachten, Sie bräuchten dafür einen Abschluss in Informatik, habe ich gute Nachrichten: Es ist einfacher, als Sie denken.
Warum sollte man ein lokales LLM (KI) verwenden?
Bevor wir ins Detail gehen, sprechen wir über das Warum. Das lokale Ausführen von LLMs (KI) bietet einige echte Vorteile:
- Datenschutz: Ihre Gespräche verlassen niemals Ihren Computer. Kein Unternehmen speichert, analysiert oder trainiert mit Ihren Daten.
- Kein Internet erforderlich: Nach der Einrichtung können Sie Ihre KI überall nutzen: im Flugzeug, im Café mit wackeliger WLAN-Verbindung oder mitten im Nirgendwo.
- Es ist kostenlos: Nach der anfänglichen Einrichtung fallen keine Abonnementgebühren oder API-Kosten an.
- Es gehört Ihnen: Sie haben die volle Kontrolle. Keine Ratenbegrenzungen, keine Inhaltsfilter, keine Änderungen der Nutzungsbedingungen.
Was Sie benötigen
Hier ist, was ich für den Anfang brauchte (und Sie werden dasselbe benötigen):
- Ein einigermaßen moderner Computer (Windows, Mac oder Linux)
- Etwa 30 Minuten Ihrer Zeit
- Rund 4–8 GB freien Speicherplatz (abhängig davon, welches Modell Sie wählen)
Das war's schon. Keine teure Grafikkarte erforderlich, obwohl die Dinge schneller laufen, wenn Sie eine besitzen.
Was ist llama.cpp?
Bevor wir mit der Installation beginnen, erkläre ich Ihnen, was wir eigentlich installieren.
llama.cpp ist eine Software, mit der Sie große Sprachmodelle (KI) auf Ihrem Computer ausführen können. Stellen Sie es sich als den Motor vor, der alles zum Laufen bringt. Diese Modelle sind nur Dateien, ähnlich wie Video- oder Musikdateien. llama.cpp ist der Player, der weiß, wie man sie benutzt.
Es ist Open Source, kostenlos und wird aktiv gewartet. Es funktioniert auf Mac, Windows und Linux und ist so konzipiert, dass es auch auf normalen Computern ohne schicke Grafikkarten schnell läuft.
Installation
Der einfachste Weg, llama.cpp zu installieren, ist über einen Paketmanager.
Wenn Sie einen Mac oder Linux verwenden
Öffnen Sie Ihr Terminal und geben Sie Folgendes ein:
brew install llama.cppDas ist die Installation. Ernsthaft.
Wenn Sie Windows verwenden
Öffnen Sie PowerShell und führen Sie Folgendes aus:
winget install llama.cppIhr erstes KI-Modell ausführen
Jetzt wird es spannend. Sie müssen Modell-Dateien nicht manuell herunterladen oder herausfinden, wo Sie sie ablegen sollen. Das Tool erledigt das alles für Sie.
So geben Sie ein, um mit einer KI zu chatten:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Dieser Befehl lädt das Llama 3.2 3B Modell von Hugging Face herunter und führt es aus.
Lassen Sie mich aufschlüsseln, was dieser Befehl in einfachem Deutsch bewirkt:
llama-clistartet die Chat-Oberfläche-hfweist es an, von Hugging Face (einem Repository für LLMs) herunterzuladenbartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0ist das spezifische zu verwendende Modell
Die Modellkennung besteht aus drei Teilen, getrennt durch Schrägstriche und einen Doppelpunkt:
bartowskiist der Benutzername desjenigen, der das Modell auf Hugging Face hochgeladen hatLlama-3.2-3B-Instruct-GGUFist der Name des Repositorys, das das Modell enthältQ8_0ist die spezifische Quantisierungsversion (Qualität vs. Größe)
Wenn Sie diesen Befehl ausführen, wird das Modell automatisch heruntergeladen (was beim ersten Mal ein paar Minuten dauern kann). Danach können Sie mit dem Chatten beginnen. Geben Sie Ihre Fragen ein, und die KI antwortet direkt in Ihrem Terminal.
Wie man verschiedene Modelle findet und verwendet
Das oben erwähnte Modell (Llama 3.2) ist ein guter Ausgangspunkt. Es ist relativ klein und schnell, selbst auf bescheidener Hardware. Aber es gibt Hunderte anderer Modelle, die Sie ausprobieren können.
Modelle auf Hugging Face finden
GGUF ist das Dateiformat, das llama.cpp verwendet. Modelle auf Hugging Face liegen in verschiedenen Formaten vor, aber llama.cpp benötigt speziell GGUF-Dateien.
Gehen Sie zu huggingface.co/models und suchen Sie nach GGUF. Achten Sie auf Repositorys, deren Name mit -GGUF endet.
Wenn Sie ein Modell gefunden haben, das Sie ausprobieren möchten, klicken Sie darauf und suchen Sie nach dem Repository-Namen. Wenn Sie beispielsweise bartowski/Qwen2.5-7B-Instruct-GGUF sehen, können Sie Folgendes ausführen:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Tipps zur Auswahl von Modellen:
- Kleinere Zahlen = schneller, aber weniger leistungsfähig: Ein 3B-Modell ist schneller als ein 7B-Modell, das wiederum schneller ist als ein 13B-Modell. Die Zahl bezieht sich auf die Milliarden von Parametern, die das Modell besitzt.
- Achten Sie auf „Instruct“ oder „Chat“ im Namen: Diese Modelle sind speziell für Konversationen trainiert.
- Der Teil :Q8_0: Dies ist die Quantisierungsstufe. Q8_0 bietet eine gute Balance zwischen Qualität und Größe. Q4_0 ist kleiner/schneller, aber etwas geringer in der Qualität.
Der nächste Schritt: Einen KI-Server ausführen
Sobald Sie mit dem einfachen Chatten vertraut sind, können Sie das Ganze auf die nächste Stufe heben, indem Sie Ihre KI als Server ausführen. Dadurch können Sie über Ihren Webbrowser mit ihr chatten und sie mit anderen Anwendungen nutzen.
Führen Sie diesen Befehl aus:
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Sie sehen eine Ausgabe wie diese:
main: server is listening on http://127.0.0.1:8080 - starting the main loopÖffnen Sie nun http://127.0.0.1:8080 (oder http://localhost:8080) in Ihrem Webbrowser. Sie sehen eine Chat-Oberfläche, über die Sie direkt aus dem Browser mit Ihrer KI sprechen können. Keine zusätzliche Software erforderlich.
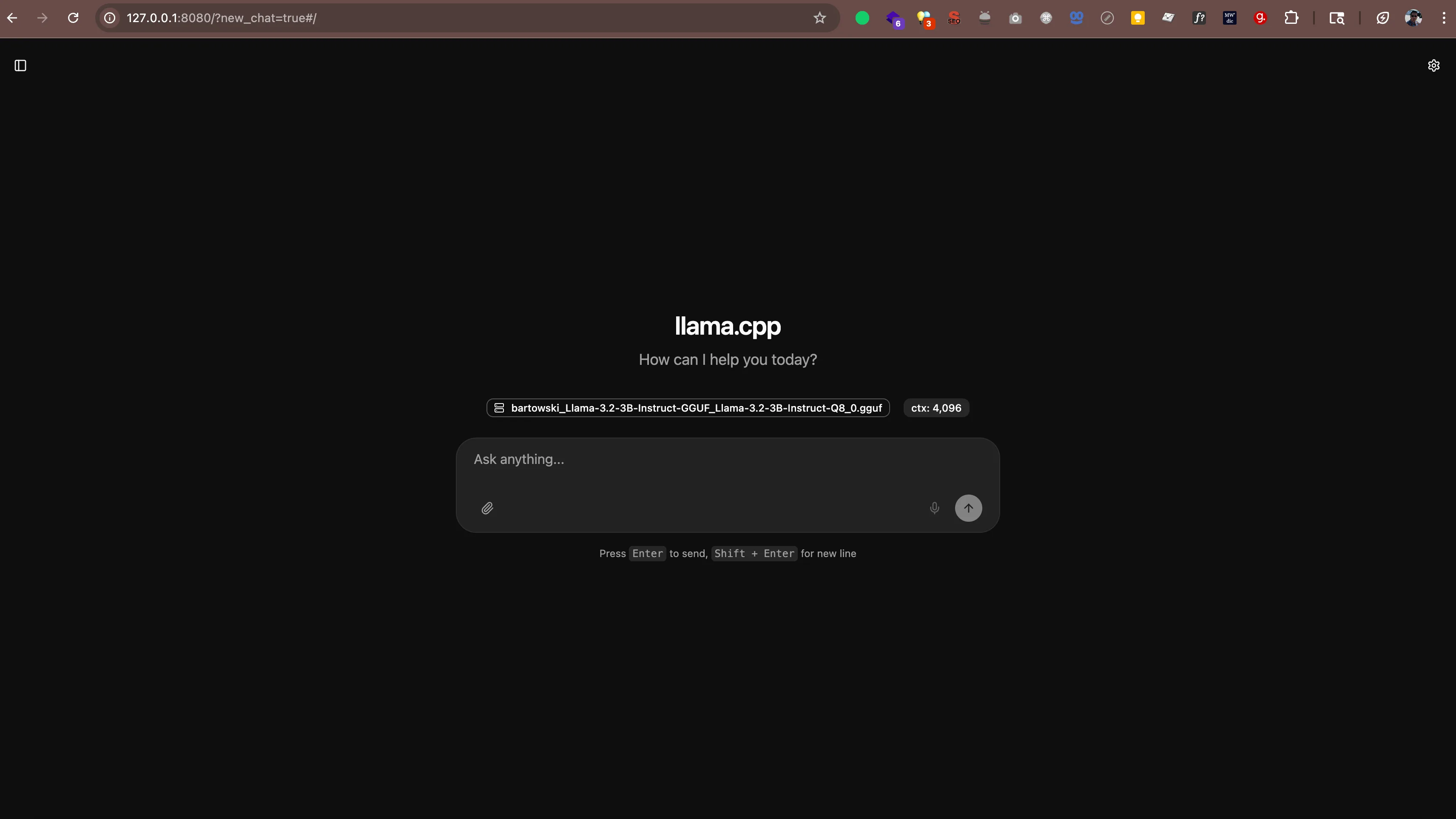
Der Server funktioniert auch mit jeder Anwendung, die OpenAIs API-Format unterstützt. Das bedeutet, Sie können Tools wie Folgendes verwenden:
- Continue.dev (KI-Coding-Assistent in VS Code)
- Open WebUI (eine ChatGPT-ähnliche Oberfläche)
- Jede andere App, die benutzerdefinierte API-Endpunkte unterstützt
Wo die Modelle gespeichert werden
Wenn Sie diese Befehle ausführen, werden die Modelle automatisch in einem Cache-Ordner heruntergeladen. Standardmäßig befindet sich dieser in Ihrem Home-Verzeichnis unter .cache/llama.cpp.
Wenn Sie ändern möchten, wo die Modelle gespeichert werden, können Sie eine Umgebungsvariable festlegen:
# Auf Mac/Linux
export LLAMA_CACHE=/pfad/zu/ihrem/cache
# Auf Windows (PowerShell)
$env:LLAMA_CACHE="C:\pfad\zu\ihrem\cache"Wie sieht es mit der Leistung aus?
Hier sind meine Erkenntnisse zur Leistung:
- Auf neueren Macs (M1/M2/M3/M4): Modelle laufen überraschend schnell. Die M-Serie Chips verfügen über eine integrierte KI-Beschleunigung.
- Auf Windows/Linux mit einer anständigen GPU: Auch schnell. Wenn Sie eine NVIDIA-GPU haben, verwendet llama.cpp diese automatisch.
- Auf älteren Computern oder Laptops ohne GPUs: Funktioniert trotzdem! Halten Sie sich einfach an kleinere Modelle (3B oder 7B) und erwarten Sie langsamere Antworten.
Als Referenz: Auf meinem M4 Pro mit 48 GB RAM generiert ein 3B-Modell Text mit etwa 60–65 Tokens pro Sekunde. Das ist schnell genug, um sich wie ein echtes Gespräch anzufühlen.
llama.cpp vs Ollama vs vLLM
Sie haben vielleicht von anderen Tools wie Ollama oder vLLM gehört. Hier ist ein Vergleich:
Ollama
Ollama basiert auf llama.cpp. Es fügt eine einfachere Oberfläche und automatische Modellverwaltung hinzu, aber dieser Komfort geht mit einem Leistungsaufwand einher. In meinen Tests auf einem M4 Pro Mac mit 48 GB RAM war llama.cpp um eine Größenordnung schneller als Ollama, das dieselben Modelle ausführte.
Wenn Sie maximale Leistung wünschen und es Ihnen nichts ausmacht, die Befehlszeile zu verwenden, bleiben Sie bei llama.cpp. Wenn Sie eine einfachere Modellverwaltung bevorzugen und etwas langsamere Geschwindigkeiten akzeptieren können, ist Ollama gut geeignet.
vLLM
vLLM unterstützt macOS nicht. Es ist nur für Linux verfügbar und für Server-Bereitstellungen mit hohem Durchsatz und mehreren GPUs konzipiert. Wenn Sie einen Mac verwenden, ist es keine Option.
Fazit
Für Mac-Benutzer, insbesondere auf Apple Silicon (M1/M2/M3/M4), ist llama.cpp die beste Wahl. Es ist die schnellste Option und verfügt über eine native Metal-Beschleunigung. Ollama ist in Ordnung, wenn Sie eine einfachere Verwaltung wünschen. vLLM ist auf dem Mac nicht verfügbar.
Fragen, die Sie vielleicht haben
Ist das legal?
Ja. Die Modelle auf Hugging Face sind Open Source und kostenlos nutzbar. Viele werden von Meta (Facebook), Mistral AI und anderen Organisationen veröffentlicht, die die persönliche und kommerzielle Nutzung ausdrücklich gestatten.
Wird das meinen Computer verlangsamen?
Während die KI läuft, beansprucht sie CPU/GPU-Ressourcen. Aber wenn Sie sie schließen, kehrt alles zum Normalzustand zurück. Es ist, als würde man eine andere Anwendung ausführen.
Kann ich das für die Arbeit verwenden?
Das hängt von den Richtlinien Ihres Arbeitgebers ab. Da alles lokal läuft und Ihre Daten Ihren Rechner nicht verlassen, ist es im Allgemeinen sicherer als Cloud-KI. Aber fragen Sie vorher Ihre IT-Abteilung.
Muss ich online sein?
Nur für den erstmaligen Download der Modelle. Danach funktioniert alles komplett offline.
Meine Erfahrung
Ich benutze meine lokale KI jetzt schon eine Weile und bin beeindruckt. Sie ist zwar nicht ganz so leistungsfähig wie GPT-5, Claude Sonnet 4.5 oder Gemini 2.5, aber für viele Aufgaben (E-Mails schreiben, Ideen sammeln, Fragen beantworten) ist sie mehr als ausreichend.
Was ich am meisten schätze, ist der Aspekt des Datenschutzes. Meine Gespräche bleiben auf meinem Rechner. Es werden keine Daten an externe Server gesendet. Es werden keine Trainingsdatensätze irgendwohin eingespeist. Das macht sie besser für die Arbeit mit vertraulichen Informationen geeignet als Cloud-KI, obwohl Sie sich dennoch an die Sicherheitsrichtlinien Ihrer Organisation halten sollten.
Ist sie perfekt? Nein. Die Antworten können manchmal langsam sein, wenn ich ein größeres Modell ausführe. Und die Qualität erreicht nicht ganz das Niveau der besten Cloud-KIs. Aber für einen kostenlosen, privaten, jederzeit verfügbaren Assistenten? Diesen Kompromiss gehe ich gerne ein.