Почему я выбрал Server-Sent Events вместо WebSockets для потоковой передачи ответов ИИ
Когда я создавал Kindle-ChatGPT, мне нужно было потоково передавать ответы AI клиенту в реальном времени. Вы знаете это приятное ощущение, когда ChatGPT печатает свой ответ слово за словом? Я хотел добиться того же эффекта.
Моей первой мыслью было использовать WebSockets. Это же стандартное решение для связи в реальном времени, верно? Но после небольшого исследования я понял, что есть более простое и изящное решение, которое было на виду: Server-Sent Events (SSE).
Что такое Server-Sent Events?
Server-Sent Events — это стандарт, который позволяет серверам отправлять данные клиентам по одному HTTP-соединению. В отличие от WebSockets, SSE однонаправленны: сервер отправляет данные клиенту, но не наоборот.
Протокол на удивление прост. Сервер отвечает с Content-Type: text/event-stream и отправляет данные в таком формате:
data: Hello
data: World
data: {"message": "JSON тоже работает"}
Каждое сообщение предваряется префиксом data: и отделяется двумя символами новой строки. Вот и всё. Никаких рукопожатий, парсинга фреймов или обновления соединения.
Почему SSE, а не WebSockets?
Суть потоковой передачи ответов AI в том, что клиент отправляет вопрос, а сервер потоково передает ответ. Это, по сути, однонаправленный поток. Зачем мне настраивать двунаправленную связь, если мне нужны данные только в одну сторону?
WebSockets сработали бы, но они несут с собой накладные расходы:
- Обновление соединения: WebSockets требуют рукопожатия для обновления HTTP
- Управление постоянным соединением: Вам нужно обрабатывать логику переподключения, heartbeats и состояние соединения
- Сложность инфраструктуры: Некоторые прокси и CDN плохо работают с WebSockets
- Больше кода: И клиенту, и серверу требуются более сложные реализации
SSE, с другой стороны:
- Использует стандартный HTTP: Работает через любой прокси, CDN или балансировщик нагрузки, который обрабатывает HTTP
- Встроенное переподключение: API
EventSourceбраузера автоматически переподключается - Простой протокол: Просто текст поверх HTTP
- Нативная поддержка браузером: На клиенте библиотеки не нужны
Для моего сценария использования — потоковой передачи текста из модели AI — SSE был очевидным выбором.
Как API Gemini использует SSE
Вот что я не сразу понял: API Gemini от Google нативно поддерживает SSE для потоковой передачи ответов. Вам просто нужно добавить ?alt=sse к конечной точке:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
API возвращает поток событий, каждое из которых содержит фрагмент ответа:
data: {"candidates":[{"content":{"parts":[{"text":"Hello"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" there"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":"!"}],"role":"model"}}]}
Создание прокси-сервера потоковой передачи с помощью TransformStream
Мой сервер выступает в роли прокси между клиентом и Gemini. Но я не хотел перенаправлять клиенту необработанный формат SSE от Gemini. Вложенная структура JSON (candidates[0].content.parts[0].text) излишне сложна для моего простого чат-интерфейса.
Вместо этого я использовал TransformStream для разбора событий SSE и извлечения только текста:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Оставляем неполную строку в буфере
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Грамотно обрабатываем ошибки парсинга
}
}
}
},
flush(controller) {
// Обрабатываем любые оставшиеся данные в буфере
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Обрабатываем финальные ошибки парсинга
}
}
}
});
Здесь есть тонкий, но важный момент: события SSE могут быть разделены между сетевыми фрагментами. Одна строка data: может прийти двумя частями. Буфер решает эту проблему, сохраняя неполные строки до прибытия следующего фрагмента.
Реализация на стороне клиента
На клиенте я мог бы использовать нативный API EventSource. Но поскольку мой преобразованный поток отправляет простой текст (а не формат SSE), я использовал напрямую API ReadableStream:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// Обновляем UI накопленным сообщением
setMessage(fullMessage);
}
В этом и прелесть потоковой передачи: каждый фрагмент приходит по мере его генерации AI, и мы можем немедленно обновить интерфейс.
Оптимизация для E-Ink дисплеев
Здесь мой конкретный сценарий стал интересным. Дисплеи Kindle с технологией E-Ink имеют низкую частоту обновления. Если бы я обновлял интерфейс при получении каждого фрагмента, экран постоянно бы мерцал и с трудом успевал за данными.
Решением стали обновляемые данные с ограничением частоты (throttled updates):
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Обновлять каждые 500 мс
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Всегда обновляем финальным содержимым
setMessage(fullMessage);
Это группирует обновления интерфейса в интервалы по 500 мс, при этом данные по-прежнему принимаются так быстро, как они поступают. Текст накапливается в памяти, а дисплей обновляется с частотой, которую может выдержать E-Ink экран.
Обработка ошибок и крайние случаи
В продакшн-коде необходимо обрабатывать несколько крайних случаев:
1. Сетевые ошибки в середине потока
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Обработать фрагмент
}
} catch (error) {
// Произошла сетевая ошибка
// Показать частичное сообщение + индикатор ошибки
setMessage(fullMessage + '\n\n[Соединение прервано]');
}
2. Некорректный JSON от API
Блок try-catch в TransformStream гарантирует, что один некорректный фрагмент не прервет весь поток. Мы логируем ошибку и продолжаем обработку.
3. Пустые ответы
Иногда API возвращает фрагменты без текстового содержимого. Опциональное связывание (?.) обрабатывает это без сбоев.
Когда использовать SSE против WebSockets
После этого опыта моя ментальная модель выглядит так:
Используйте SSE, когда:
- Данные в основном идут от сервера к клиенту
- Вам нужна простая реализация с минимальной инфраструктурой
- Автоматическое переподключение полезно
- Вы передаете потоком текст, логи, уведомления или события
Используйте WebSockets, когда:
- Вам нужна двунаправленная связь
- Критически важна низкая задержка (игры, совместное редактирование)
- Вы отправляете бинарные данные
- Вам нужно часто отправлять сообщения от клиента к серверу
Для приложений чата с AI SSE идеально подходит. Пользователь отправляет сообщение (обычный POST-запрос), а AI потоково передает ответ (SSE). Просто, эффективно и работает везде.
Вопросы развертывания
Я развернул это на Cloudflare Workers, и SSE заработал без какой-либо специальной настройки. Среда Workers нативно поддерживает потоковую передачу ответов:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Несколько моментов, которые стоит отметить:
- Отсутствие кэширования: Потоковые ответы никогда не должны кэшироваться
- Keep-alive: Помогает поддерживать соединение для более длинных потоков
- Content-Type: Я использовал
text/plain, так как отправляю чистый текст, а не формат SSE
Полный поток данных
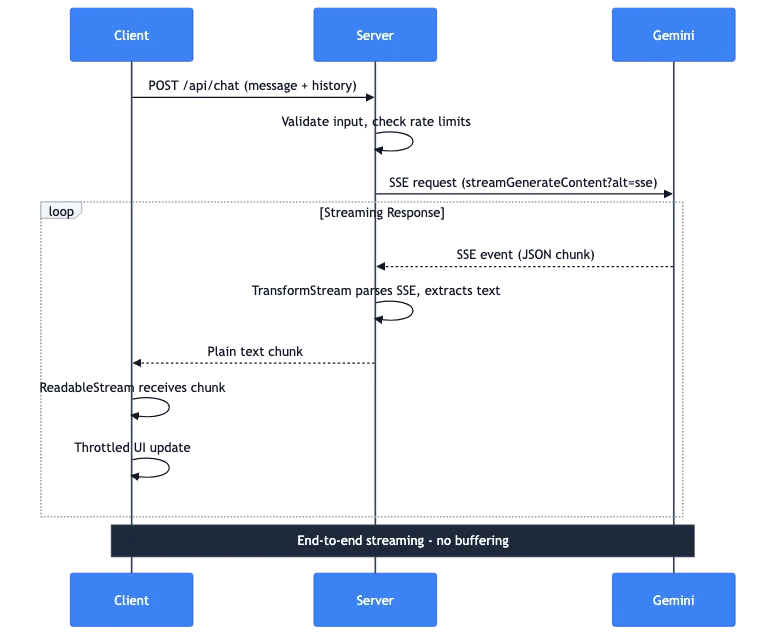
Давайте рассмотрим, что происходит, когда пользователь отправляет сообщение:
- Клиент: POST-запрос с сообщением и историей диалога
- Сервер: Проверяет входные данные, лимиты запросов
- Сервер: Выполняет SSE-запрос к API Gemini
- Gemini: Потоково передает SSE-события с JSON-фрагментами
- Сервер: TransformStream разбирает SSE, извлекает текст
- Сервер: Перенаправляет фрагменты чистого текста клиенту
- Клиент: ReadableStream получает фрагменты
- Клиент: Обновления UI с ограничением частоты отображают текст
Весь конвейер работает в режиме потоковой передачи от начала до конца. Полный ответ на сервере не буферизуется. Первый токен от Gemini достигает экрана пользователя за миллисекунды.