Как запустить открытые LLM (ИИ) на вашем компьютере?
Я настроил своего собственного ИИ-помощника, который работает полностью на моем компьютере. Не требуется подключение к интернету. Данные не отправляются в облако.
Если вы интересовались запуском собственного ИИ, но думали, что для этого нужна ученая степень в области компьютерных наук, у меня хорошие новости: это проще, чем вы думаете.
Зачем вам нужен локальный LLM (ИИ)?
Прежде чем углубляться в то, как это сделать, давайте поговорим о том, почему. Запуск LLM (ИИ) локально имеет ряд реальных преимуществ:
- Конфиденциальность: Ваши разговоры никогда не покидают ваш компьютер. Никакая компания не хранит, не анализирует и не использует ваши данные для обучения.
- Интернет не требуется: После настройки вы можете использовать свой ИИ где угодно: в самолете, в кафе с неустойчивым Wi-Fi или в глуши.
- Это бесплатно: После первоначальной настройки нет никаких абонентских плат или затрат на API.
- Он ваш: Вы контролируете все. Никаких ограничений по скорости, никаких фильтров контента, никаких изменений условий обслуживания.
Что вам понадобится
Вот что мне понадобилось, чтобы начать (и вам понадобится то же самое):
- Достаточно современный компьютер (Windows, Mac или Linux)
- Около 30 минут вашего времени
- Около 4–8 ГБ свободного места на диске (в зависимости от выбранной модели)
Вот и все. Дорогая видеокарта не требуется, хотя если она у вас есть, все будет работать быстрее.
Что такое llama.cpp?
Прежде чем мы перейдем к установке, позвольте мне объяснить, что именно мы устанавливаем.
llama.cpp — это программное обеспечение, которое позволяет запускать большие языковые модели (ИИ) на вашем компьютере. Представьте, что это двигатель, который заставляет все работать. Эти модели — просто файлы данных, как видео- или музыкальные файлы. llama.cpp — это проигрыватель, который знает, как их использовать.
Это открытый исходный код, бесплатный и активно поддерживаемый. Он работает на Mac, Windows и Linux и разработан так, чтобы быть быстрым даже на обычных компьютерах без модных видеокарт.
Установка
Самый простой способ установить llama.cpp — через менеджер пакетов.
Если у вас Mac или Linux
Откройте терминал и введите:
brew install llama.cppВот и вся установка. Серьезно.
Если у вас Windows
Откройте PowerShell и выполните:
winget install llama.cppЗапуск вашей первой модели ИИ
Вот где становится интересно. Вам не нужно вручную скачивать файлы моделей или выяснять, куда их поместить. Инструмент делает все это за вас.
Вот что нужно ввести, чтобы начать общаться с ИИ:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Это скачивает и запускает модель Llama 3.2 3B с Hugging Face.
Позвольте мне объяснить, что это делает простыми словами:
llama-cliзапускает интерфейс чата-hfуказывает ему скачивать с Hugging Face (репозиторий LLM)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0— это конкретная модель для использования
Идентификатор модели состоит из трех частей, разделенных слэшами и двоеточием:
bartowski— это имя пользователя, который загрузил модель на Hugging FaceLlama-3.2-3B-Instruct-GGUF— это имя репозитория, содержащего модельQ8_0— это конкретная версия квантования (качество против размера)
Когда вы выполните эту команду, модель загрузится автоматически (в первый раз это может занять несколько минут), а затем вы сможете начать общаться. Вводите свои вопросы, и ИИ отвечает прямо в вашем терминале.
Как найти и использовать разные модели
Модель, которую я упомянул выше (Llama 3.2), — хорошее начало. Она относительно небольшая и быстрая даже на скромном оборудовании. Но есть сотни других моделей, которые вы можете попробовать.
Поиск моделей на Hugging Face
GGUF — это формат файлов, который использует llama.cpp. Модели на Hugging Face поставляются в разных форматах, но llama.cpp конкретно нужны файлы GGUF.
Перейдите на huggingface.co/models и найдите GGUF. Ищите репозитории, имена которых заканчиваются на -GGUF.
Когда вы найдете модель, которую хотите попробовать, нажмите на нее и посмотрите на имя репозитория. Например, если вы видите bartowski/Qwen2.5-7B-Instruct-GGUF, вы можете выполнить:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Советы по выбору моделей:
- Меньшие числа = быстрее, но менее мощные: Модель 3B быстрее, чем модель 7B, которая быстрее, чем модель 13B. Число указывает, сколько миллиардов параметров у модели.
- Ищите «Instruct» или «Chat» в названии: Эти модели специально обучены для диалогов.
- Часть :Q8_0: Это уровень квантования. Q8_0 — хороший баланс качества и размера. Q4_0 меньше/быстрее, но немного ниже по качеству.
Шаг вперед: Запуск сервера ИИ
Как только вы освоите базовый чат, вы можете перейти на новый уровень, запустив свой ИИ в качестве сервера. Это позволит вам общаться с ним из веб-браузера и использовать его с другими приложениями.
Выполните эту команду:
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Вы увидите вывод, похожий на:
main: server is listening on http://127.0.0.1:8080 - starting the main loopТеперь откройте http://127.0.0.1:8080 (или http://localhost:8080) в вашем веб-браузере. Вы увидите интерфейс чата, где сможете общаться со своим ИИ прямо из браузера. Дополнительное программное обеспечение не требуется.
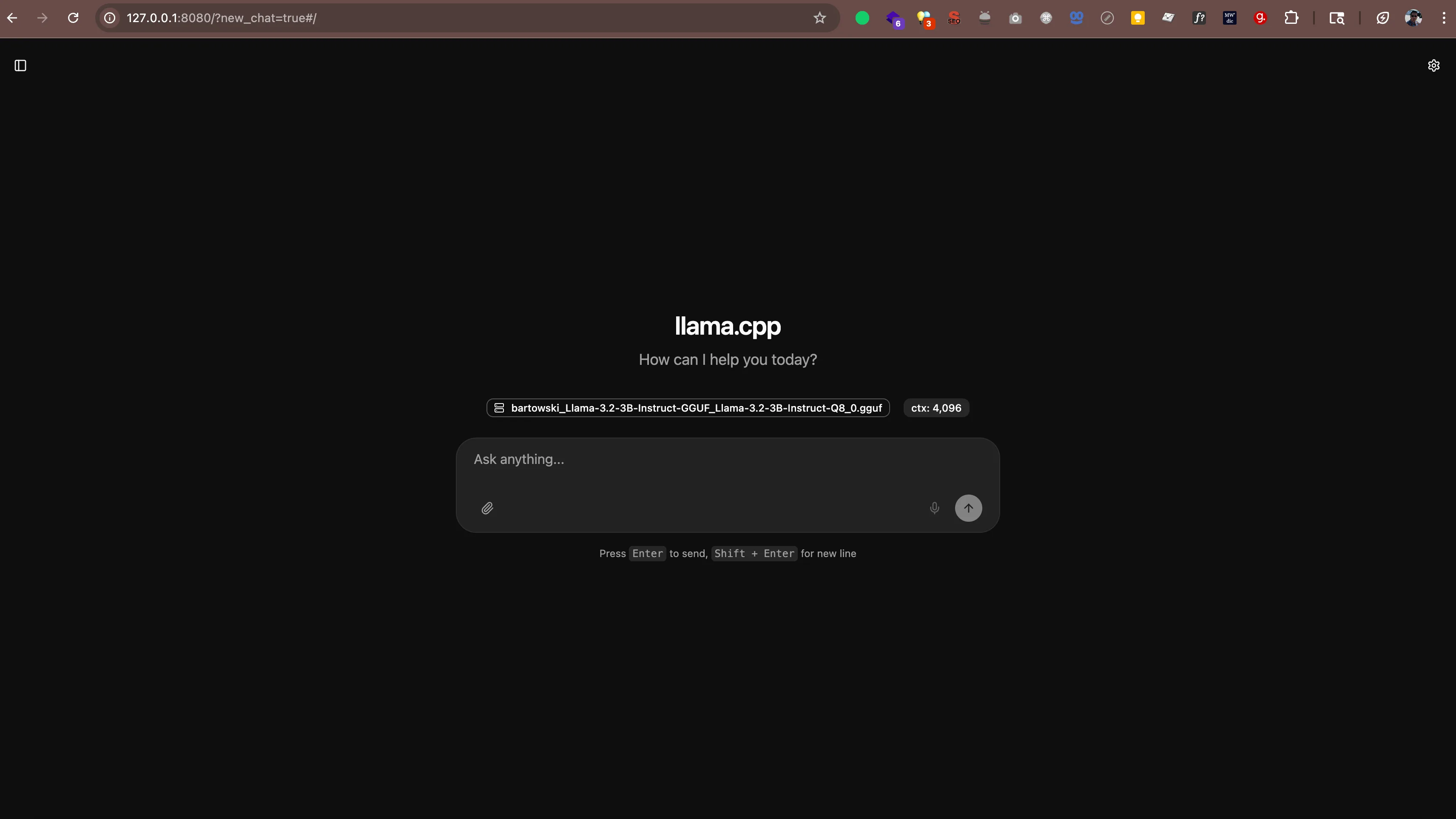
Сервер также работает с любым приложением, которое поддерживает формат API OpenAI. Это означает, что вы можете использовать такие инструменты, как:
- Continue.dev (помощник по кодированию ИИ в VS Code)
- Open WebUI (интерфейс, похожий на ChatGPT)
- Любое другое приложение, поддерживающее пользовательские конечные точки API
Где хранятся модели
Когда вы запускаете эти команды, модели автоматически загружаются в папку кэша. По умолчанию она находится в вашем домашнем каталоге в .cache/llama.cpp.
Если вы хотите изменить место хранения моделей, вы можете установить переменную окружения:
# На Mac/Linux
export LLAMA_CACHE=/path/to/your/cache
# На Windows (PowerShell)
$env:LLAMA_CACHE="C:\path\to\your\cache"А как насчет производительности?
Вот что я узнал о производительности:
- На новых Mac (M1/M2/M3/M4): Модели работают на удивление быстро. Чипы серии M имеют встроенное ускорение ИИ.
- На Windows/Linux с приличной видеокартой: Тоже быстро. Если у вас есть видеокарта NVIDIA, llama.cpp будет использовать ее автоматически.
- На старых компьютерах или ноутбуках без видеокарт: Все равно работает! Просто придерживайтесь меньших моделей (3B или 7B) и ожидайте более медленных ответов.
Для справки: на моем M4 Pro с 48 ГБ ОЗУ 3B модель генерирует текст со скоростью около 60–65 токенов в секунду. Этого достаточно быстро, чтобы ощущаться как реальный разговор.
llama.cpp против Ollama против vLLM
Возможно, вы слышали о других инструментах, таких как Ollama или vLLM. Вот как они соотносятся:
Ollama
Ollama построен на базе llama.cpp. Он добавляет более простой интерфейс и автоматическое управление моделями, но за это удобство приходится платить снижением производительности. В моих тестах на Mac M4 Pro с 48 ГБ ОЗУ llama.cpp был на порядок быстрее, чем Ollama, запускающий те же модели.
Если вам нужна максимальная производительность, и вы не против использовать командную строку, придерживайтесь llama.cpp. Если вы предпочитаете более простое управление моделями и готовы смириться с немного меньшей скоростью, Ollama подойдет.
vLLM
vLLM не поддерживает macOS. Он предназначен только для Linux и разработан для высокопроизводительных серверных развертываний с несколькими графическими процессорами. Если у вас Mac, это не вариант.
Суть
Для пользователей Mac, особенно на Apple Silicon (M1/M2/M3/M4), llama.cpp — лучший выбор. Это самый быстрый вариант с нативной аппаратной акселерацией Metal. Ollama подойдет, если вам нужно более простое управление. vLLM недоступен на Mac.
Вопросы, которые могут у вас возникнуть
Это законно?
Да. Модели на Hugging Face являются открытым исходным кодом и бесплатны для использования. Многие из них опубликованы Meta (Facebook), Mistral AI и другими организациями, которые прямо разрешают личное и коммерческое использование.
Замедлит ли это мой компьютер?
Пока ИИ работает, он использует ресурсы ЦП/видеокарты. Но когда вы его закрываете, все возвращается в норму. Это как запуск любого другого приложения.
Могу ли я использовать это для работы?
Это зависит от политик вашей работы. Поскольку все работает локально, и ваши данные не покидают вашу машину, это, как правило, безопаснее, чем облачный ИИ. Но сначала проконсультируйтесь с вашим ИТ-отделом.
Нужна ли мне постоянная связь?
Только для первоначальной загрузки моделей. После этого все работает полностью в автономном режиме.
Мой опыт
Я пользуюсь своим локальным ИИ, и я впечатлен. Он не так хорош, как GPT-5, Claude Sonnet 4.5 или Gemini 2.5, но для многих задач (написание электронных писем, мозговой штурм идей, ответы на вопросы) его более чем достаточно.
Что я ценю больше всего, так это аспект конфиденциальности. Мои разговоры остаются на моей машине. Никакие данные не отправляются на внешние серверы. Никакие наборы данных для обучения никуда не передаются. Это делает его более подходящим для работы с конфиденциальной информацией по сравнению с облачным ИИ, хотя вам все равно следует соблюдать политики безопасности вашей организации.
Идеально ли это? Нет. Ответы иногда могут быть медленными, если я запускаю более крупную модель. И качество не совсем на уровне лучших облачных ИИ. Но для бесплатного, конфиденциального, всегда доступного помощника? Я принимаю этот компромисс.