Добавление собственного ИИ-помощника на ваш сайт без корпоративных затрат
Пользовательские RAG-решения, такие как чат-боты с использованием AI, не обязательно должны быть дорогими. Вы можете запускать их бесплатно, используя щедрый бесплатный тариф Cloudflare.
Корпоративные платформы, такие как AWS Kendra или Azure AI Search, могут стоить тысячи в месяц, в то время как такие варианты, как стартовый тариф Pinecone или решения с самостоятельным размещением с использованием pgvector, предлагают более бюджетные альтернативы. Поучаствовав в нескольких RAG-проектах, я обнаружил, что Cloudflare AI Search может быть хорошим вариантом в зависимости от ваших потребностей. Он подойдет не для всех сценариев, но во многих случаях берет на себя основную нагрузку.
В этом посте я расскажу, как я создал чат-бота для этого сайта с помощью Cloudflare AI Search. Я рассмотрю, что такое RAG, как AI Search упрощает конвейер, детали реализации (потоковая передача, хранение, ограничение скорости), реальные затраты и как это масштабируется до бизнес-сценариев.
Хотя это личный сайт (мой цифровой сад), та же архитектура применима независимо от того, индексируете ли вы личный веб-сайт или документацию компании.
Что такое RAG?
RAG (Retrieval-Augmented Generation — Генерация с дополненным поиском) — это шаблон, который основывает ответы LLM на ваших фактических данных. Вместо того чтобы полагаться исключительно на данные, на которых обучалась модель, RAG извлекает соответствующий контент из ваших документов и включает его в запрос (промпт).
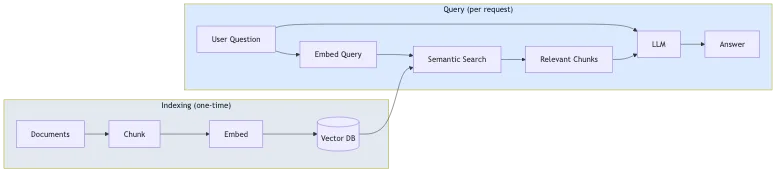
Процесс состоит из двух этапов:
- Индексирование (единоразово): Ваши документы разбиваются на фрагменты (чанки), преобразуются в векторные представления (эмбеддинги) и сохраняются в векторной базе данных.
- Запрос (на каждое обращение): Вопрос пользователя преобразуется в эмбеддинг, похожие фрагменты извлекаются с помощью семантического поиска, а LLM генерирует ответ, используя эти фрагменты в качестве контекста.
Этот подход уменьшает галлюцинации, поскольку модель отвечает на основе вашего контента, а не только на основе общих знаний. Это также означает, что вам не нужно дообучать модель каждый раз, когда меняется ваш контент.
Что на самом деле делает Cloudflare AI Search
Прежде чем углубляться в реализацию, стоит понять, что AI Search (ранее называвшийся AutoRAG) предоставляет «из коробки»:
- Автоматическое индексирование: Укажите на свой веб-сайт или источник данных, и он автоматически сканирует и индексирует ваш контент.
- Векторные представления (эмбеддинги): Он генерирует и управляет эмбеддингами для семантического поиска.
- Конвейер RAG: Он извлекает соответствующий контент и генерирует ответы, используя этот контекст.
- Непрерывные обновления: Когда ваш контент меняется, индекс обновляется автоматически.
Это означает, что вам не нужно самостоятельно создавать логику для разбиения на чанки, создания эмбеддингов, векторного хранения или извлечения данных. AI Search берет все это на себя.
Обзор архитектуры
Вот что я на самом деле построил:
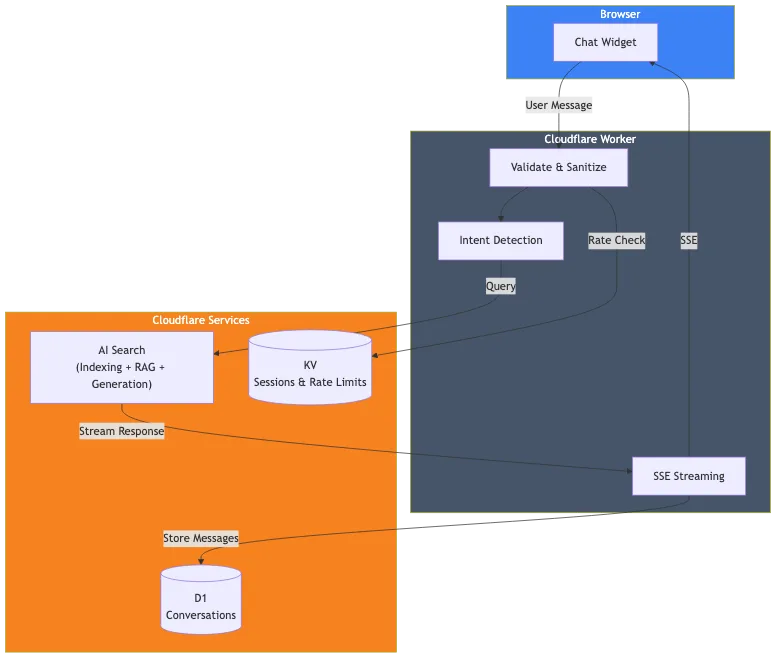
Компоненты:
- Cloudflare AI Search: Индексирует этот веб-сайт и управляет конвейером RAG.
- Cloudflare Worker: Обрабатывает запросы, валидацию и потоковую передачу ответов.
- Cloudflare D1: Хранит историю разговоров для аналитики.
- Cloudflare KV: Управляет сессиями и ограничением скорости.
Основная реализация
Сам вызов AI Search прост. Вот ключевая часть:
// Получаем привязку AI из контекста Cloudflare
const ai = await getCloudflareAI();
// Вызываем AI Search
const aiSearch = ai.autorag('your-ai-search-instance');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});На этом часть RAG завершена. AI Search принимает запрос пользователя, ищет контент моего проиндексированного веб-сайта, извлекает соответствующие фрагменты и генерирует ответ, используя этот контекст.
Настройка AI Search
Чтобы использовать AI Search, вам необходимо:
- Создать экземпляр AI Search на панели управления Cloudflare.
- Подключить источник данных (в моем случае — этот веб-сайт).
- Дождаться завершения начального индексирования.
- Добавить привязку AI в ваш wrangler.toml.
# wrangler.toml
[ai]
binding = "AI"После настройки AI Search постоянно отслеживает ваш источник данных и обновляет индекс при изменении контента.
Системный промпт
Системный промпт определяет, как должен вести себя ИИ. Здесь вы формируете личность и границы чат-бота:
function getSystemPrompt(locale: string): string {
return `Вы — полезный ИИ-помощник на портфолио-сайте Дэвида Лора.
## КРИТИЧЕСКИЕ ПРАВИЛА:
1. ВСЕГДА отвечайте на ${languageNames[locale]}
2. ОТВЕЧАЙТЕ ТОЛЬКО на вопросы о Дэвиде Лоре — вы НЕ являетесь универсальным помощником
3. Используйте предоставленный контекст о Дэвиде — не придумывайте информацию
## Ваше поведение:
- Будьте полезны и профессиональны
- Делайте ответы краткими (максимум 2-3 абзаца)
- При необходимости упомяните, что можно забронировать звонок или отправить электронное письмо
- Не обсуждайте цены — предложите обсудить напрямую
- Не притворяйтесь Дэвидом — вы его ИИ-помощник`;
}Раздел критических правил важен. Без явных границ чат-бот попытается ответить на общие вопросы, что не подходит для помощника на портфолио.
Потоковая передача ответов
Никто не хочет ждать полного ответа, чтобы что-то увидеть. AI Search поддерживает потоковую передачу «из коробки» с помощью stream: true. Вы можете передавать ответ напрямую клиенту с помощью Server-Sent Events (SSE), предоставляя пользователям знакомый эффект набора текста в стиле ChatGPT.
Хранение разговоров с помощью D1
Если вы хотите анализировать разговоры или улучшать своего чат-бота с течением времени, вы можете хранить их в Cloudflare D1 (их бессерверный SQLite). Просто выполняйте операции записи в базу данных в фоновом режиме, чтобы они не блокировали потоковую передачу ответа.
Ограничение скорости с помощью KV
Публичные API нуждаются в защите. Я использую Cloudflare KV для простого ограничения скорости:
const RATE_LIMIT_WINDOW_MS = 60000; // 1 минута
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 сообщений в минуту
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// Новое окно
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Ограничение скорости
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}Локальная разработка
Для локальной разработки я использую npx wrangler dev, который запускает Worker локально, подключаясь к моим производственным сервисам Cloudflare (AI Search, D1, KV). Это дает мне среду, близкую к производственной, без необходимости развертывания:
npx wrangler devКод Worker выполняется на моей машине, но привязки подключаются к реальным удаленным сервисам. Это означает, что локальная разработка действительно использует вашу квоту нейронов, но это самый точный способ тестирования перед развертыванием.
Сколько мне это стоило
Вот хорошие новости: весь этот стек можно запустить на бесплатном тарифе Cloudflare. Платный план не требуется.
| Сервис | Лимиты бесплатного тарифа |
|---|---|
| AI Search | Доступен на всех планах (включая бесплатный) |
| Workers AI | 10 000 нейронов/день |
| D1 | 5 млн чтений/день, 100 тыс. записей/день, 5 ГБ хранилища |
| KV | 100 тыс. чтений/день, 1 тыс. записей/день, 1 ГБ хранилища |
| Workers | 100 тыс. запросов/день |
Основным лимитом, с которым вы столкнетесь, являются нейроны Workers AI. Давайте посчитаем.
Workers AI (основная стоимость)
Вы получаете 10 000 бесплатных нейронов в день (около 300 000 в месяц). Типичное взаимодействие в чате с AI Search потребляет примерно 500–1000 нейронов в зависимости от длины ответа. Это означает:
- ~300–600 сообщений в чате в день, прежде чем превысить бесплатный лимит.
- ~9 000–18 000 сообщений в месяц включено.
Для большинства личных сайтов и малого бизнеса этого более чем достаточно, чтобы работать полностью бесплатно. Сверх этого вы платите $0,011 за каждые 1000 нейронов. Оживленный чат-бот, обрабатывающий 1000 сообщений в день, будет стоить примерно на $5–10 в месяц дополнительно.
Другие сервисы (щедрые лимиты)
Другие лимиты бесплатного тарифа щедры:
- Запросы Workers: 100 тыс./день. Это ~100 тыс. сообщений в чате ежедневно, прежде чем будут достигнуты лимиты.
- Чтения D1: 5 млн/день. Каждый чат использует несколько чтений, так что тысячи чатов в день.
- Записи D1: 100 тыс./день. Каждое сообщение сохраняет 2 строки, то есть ~50 тыс. сообщений/день.
- Чтения KV: 100 тыс./день. Ограничение скорости использует ~2 чтения на сообщение.
Для большинства сайтов нейроны Workers AI — единственный лимит, которого вы реально можете достичь. Остальные сервисы имеют ежедневные лимиты, которые сбрасываются, предоставляя вам достаточно пространства для маневра.
Что я не строил
Стоит отметить, что AI Search сделал для меня:
- Разбиение документов на чанки: Я не писал никакой логики разбиения.
- Генерация эмбеддингов: AI Search генерирует эмбеддинги и управляет ими.
- Векторное хранилище: Нет необходимости настраивать Vectorize отдельно.
- Логика извлечения: AI Search обрабатывает семантический поиск.
- Обновления индекса: Изменения контента подхватываются автоматически.
Если бы я создавал это с нуля с отдельными эмбеддингами, векторной базой данных и конвейером извлечения, это потребовало бы значительно больше работы. AI Search абстрагирует все это.
Масштабирование до бизнес-сценариев
Хотя я создал это для своего личного сайта, та же модель применима и к бизнес-сценариям. AI Search поддерживает различные источники данных, помимо веб-сайтов:
Поддержка клиентов
Подключите AI Search к вашей документации, справочному центру или базе знаний. Чат-бот может отвечать на вопросы о продуктах, запросы по устранению неполадок и вопросы о политике без обучения пользовательской модели. Добавьте логику для эскалации к живым агентам при необходимости.
Внутренний помощник по знаниям
Индексируйте вашу корпоративную вики, Confluence или внутреннюю документацию. Сотрудники могут задавать вопросы на естественном языке вместо поиска по папкам. Системный промпт определяет границы доступа и стиль ответа.
Консультант по продуктам электронной коммерции
Индексируйте страницы вашего товарного каталога. Покупатели могут спросить: «Какой ноутбук подойдет для видеомонтажа до 1000 долларов?» и получить ответы, основанные на ваших реальных запасах. Перенаправляйте клиентов, готовых к покупке, к оформлению заказа.
Что меняется при масштабировании
Основная архитектура остается прежней. Меняется следующее:
- Источник данных: Вместо личного веб-сайта вы подключаете контент вашего бизнеса.
- Системный промпт: Адаптирован под ваш фирменный стиль и сценарий использования.
- Бизнес-логика: Пользовательская маршрутизация на основе потребностей пользователя.
- Ограничения скорости: Настраиваются в зависимости от ожидаемого трафика.
- Аутентификация: Добавьте аутентификацию пользователя, если индексируете закрытый контент.
AI Search справляется со сложностью RAG независимо от того, индексируете ли вы 50 страниц или 50 000.
Гибкость моделей
AI Search не привязан к одной модели. У вас есть варианты:
Модели генерации: AI Search поддерживает модели от нескольких поставщиков, включая Anthropic (Claude 3.5, Claude 4), Google (Gemini 2.5 Flash/Pro), OpenAI (GPT-4o, GPT-5), а также Cerebras, Grok, Groq и Workers AI. Вы можете выбрать «Умное значение по умолчанию» (Smart Default), которое Cloudflare обновляет автоматически, или выбрать конкретную модель. Модели генерации можно даже переопределять для каждого запроса через API.
Модели эмбеддингов: Варианты включают модели text-embedding-3 от OpenAI, Gemini Embedding от Google и модели BGE от Workers AI. Модель эмбеддингов устанавливается во время первоначальной настройки и не может быть изменена позже (это потребует повторного индексирования всего).
Используйте свою модель: Если поддерживаемые модели не соответствуют вашим потребностям, вы можете использовать собственную модель генерации через AI Gateway или используя AI Search только для извлечения данных и отправляя результаты в любой внешний LLM.
Ограничения
Этот подход имеет некоторые ограничения:
- Специфичность Cloudflare: AI Search работает только в экосистеме Cloudflare.
- Ограниченная настройка извлечения: Вы можете настроить размер чанка и перекрытие, но не базовую стратегию разбиения на чанки или алгоритм извлечения.
- Ограниченные источники данных: AI Search поддерживает веб-сайты и хранилище R2 (для PDF, документов и т. д.), но не произвольные базы данных или API напрямую.
Для более сложных сценариев (пользовательское разбиение на чанки, несколько разнородных источников данных или специализированное извлечение) вам потребуется самостоятельно создать большую часть конвейера, используя напрямую Vectorize и Workers AI.
Попробуйте чат-бота в углу этой страницы. Он работает именно так, как я описал здесь.
Если вы создаете что-то похожее и хотите обсудить детали, давайте поговорим.