Por qué elegí Server-Sent Events en lugar de WebSockets para transmitir respuestas de IA
Cuando construí Kindle-ChatGPT, necesitaba transmitir las respuestas de la IA al cliente en tiempo real. ¿Conoces esa experiencia satisfactoria de ver a ChatGPT escribir su respuesta palabra por palabra? Yo quería esa misma sensación.
Mi primer instinto fue recurrir a WebSockets. Es la solución ideal para la comunicación en tiempo real, ¿verdad? Pero después de investigar un poco, me di cuenta de que había una solución más simple y elegante escondida a plena vista: Server-Sent Events (SSE).
¿Qué son los Server-Sent Events?
Server-Sent Events es un estándar que permite a los servidores enviar datos a los clientes a través de una única conexión HTTP. A diferencia de WebSockets, SSE es unidireccional: el servidor envía datos al cliente, pero no al revés.
El protocolo es sorprendentemente simple. El servidor responde con Content-Type: text/event-stream y envía los datos en este formato:
data: Hola
data: Mundo
data: {"mensaje": "El JSON también funciona"}
Cada mensaje va precedido por data: y separado por dos saltos de línea. Eso es todo. Sin apretones de manos (handshakes), sin análisis de tramas (frame parsing), sin actualizaciones de conexión.
¿Por qué SSE en lugar de WebSockets?
El quid de la cuestión al transmitir respuestas de IA es este: el cliente envía una pregunta y el servidor transmite la respuesta. Es fundamentalmente un flujo unidireccional. ¿Por qué iba a configurar una comunicación bidireccional cuando solo necesito datos en una dirección?
WebSockets funcionaría, pero conlleva una sobrecarga:
- Actualización de conexión: WebSockets requiere un handshake de actualización HTTP
- Gestión de conexión persistente: Necesitas manejar la lógica de reconexión, latidos (heartbeats) y el estado de la conexión
- Complejidad de la infraestructura: Algunos proxies y CDN no manejan bien WebSockets
- Más código: Tanto el cliente como el servidor necesitan implementaciones más complejas
SSE, por otro lado:
- Usa HTTP estándar: Funciona a través de cualquier proxy, CDN o balanceador de carga que maneje HTTP
- Reconexión integrada: La API
EventSourcedel navegador se reconecta automáticamente - Protocolo simple: Solo texto sobre HTTP
- Soporte nativo del navegador: No se necesitan librerías en el cliente
Para mi caso de uso, transmitir texto desde un modelo de IA, SSE fue la elección obvia.
Cómo usa SSE la API de Gemini
Aquí hay algo que no me di cuenta al principio: la API de Gemini de Google admite nativamente SSE para transmitir respuestas. Solo tienes que añadir ?alt=sse al endpoint:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
La API devuelve un flujo de eventos, cada uno conteniendo un fragmento (chunk) de la respuesta:
data: {"candidates":[{"content":{"parts":[{"text":"Hola"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" a"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" todos"}],"role":"model"}}]}
Construyendo un proxy de transmisión con TransformStream
Mi servidor actúa como proxy entre el cliente y Gemini. Pero no quería reenviar el formato SSE sin procesar de Gemini al cliente. La estructura JSON anidada (candidates[0].content.parts[0].text) es innecesariamente compleja para mi sencilla interfaz de chat.
En su lugar, utilicé un TransformStream para analizar los eventos SSE y extraer solo el texto:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Conservar línea incompleta en el búfer
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Manejar errores de análisis con elegancia
}
}
}
},
flush(controller) {
// Procesar cualquier dato restante en el búfer
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Manejar errores de análisis finales
}
}
}
});
Hay un detalle sutil pero importante aquí: los eventos SSE pueden dividirse en fragmentos de red. Una sola línea data: podría llegar en dos partes. El búfer maneja esto conservando las líneas incompletas hasta que llega el siguiente fragmento.
La implementación del lado del cliente
En el cliente, podría usar la API nativa EventSource. Pero como mi flujo transformado envía texto plano (no formato SSE), usé directamente la API ReadableStream:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// Actualizar la UI con el mensaje acumulado
setMessage(fullMessage);
}
Esta es la belleza de la transmisión (streaming): cada fragmento llega a medida que la IA lo genera, y podemos actualizar la UI inmediatamente.
Optimización para pantallas de tinta electrónica (e-ink)
Aquí es donde mi caso de uso específico se volvió interesante. Las pantallas de tinta electrónica de Kindle tienen tasas de refresco lentas. Si actualizaba la UI con cada fragmento, la pantalla parpadearía constantemente y tendría dificultades para seguir el ritmo.
La solución fue la actualización con limitación de velocidad (throttled updates):
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Actualizar cada 500ms
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Siempre actualizar con el contenido final
setMessage(fullMessage);
Esto agrupa las actualizaciones de la UI en intervalos de 500 ms mientras sigue recibiendo datos tan rápido como llegan. El texto se acumula en la memoria y la pantalla se actualiza a un ritmo que la pantalla de tinta electrónica puede manejar.
Manejo de errores y casos límite
El código de producción necesita manejar varios casos límite:
1. Errores de red a mitad de la transmisión
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Procesar fragmento
}
} catch (error) {
// Ocurrió un error de red
// Mostrar mensaje parcial + indicador de error
setMessage(fullMessage + '\n\n[Conexión interrumpida]');
}
2. JSON mal formado desde la API
El try-catch del TransformStream asegura que un fragmento defectuoso no rompa toda la transmisión. Registramos el error y continuamos procesando.
3. Respuestas vacías
A veces la API devuelve fragmentos sin contenido de texto. El encadenamiento opcional (?.) maneja esto con elegancia.
Cuándo usar SSE vs WebSockets
Después de esta experiencia, este es mi modelo mental:
Usar SSE cuando:
- Los datos fluyen principalmente del servidor al cliente
- Necesitas una implementación simple con infraestructura mínima
- La reconexión automática es valiosa
- Estás transmitiendo texto, registros (logs), notificaciones o eventos
Usar WebSockets cuando:
- Necesitas comunicación bidireccional
- La baja latencia es crítica (juegos, edición colaborativa)
- Estás enviando datos binarios
- Necesitas enviar mensajes frecuentes del cliente al servidor
Para las aplicaciones de chat con IA, SSE alcanza el punto óptimo. El usuario envía un mensaje (solicitud POST normal) y la IA transmite la respuesta (SSE). Simple, eficiente y funciona en todas partes.
Consideraciones de implementación (Deployment)
Implementé esto en Cloudflare Workers, y SSE funcionó sin ninguna configuración especial. El entorno de Workers admite respuestas de transmisión nativamente:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Algunas cosas a tener en cuenta:
- Sin caché: Las respuestas de transmisión nunca deben almacenarse en caché
- Keep-alive: Ayuda a mantener la conexión para transmisiones más largas
- Content-Type: Usé
text/plainya que estoy enviando texto sin procesar, no formato SSE
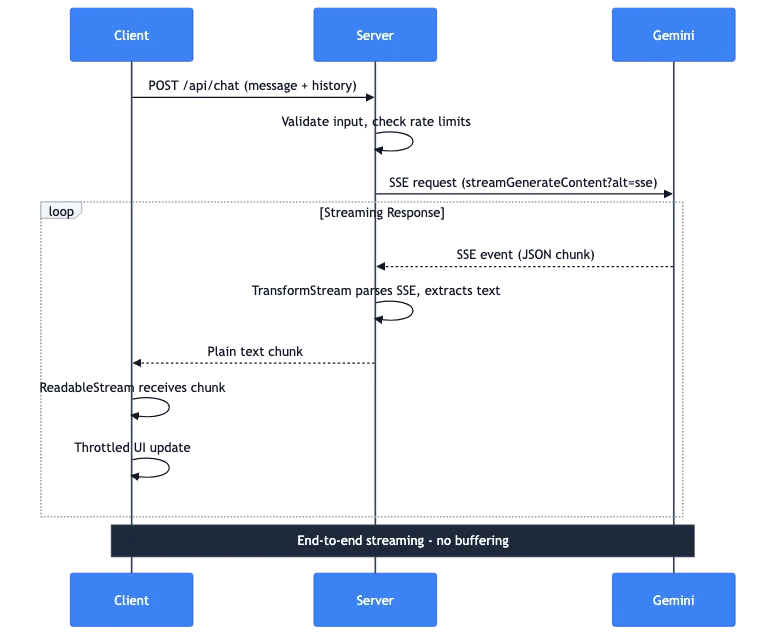
El flujo de datos completo
Permítanme explicar lo que sucede cuando un usuario envía un mensaje:
- Cliente: Solicitud POST con mensaje e historial de conversación
- Servidor: Valida la entrada, comprueba los límites de velocidad (rate limits)
- Servidor: Realiza una solicitud SSE a la API de Gemini
- Gemini: Transmite eventos SSE con fragmentos JSON
- Servidor: TransformStream analiza SSE, extrae texto
- Servidor: Reenvía fragmentos de texto plano al cliente
- Cliente: ReadableStream recibe los fragmentos
- Cliente: Las actualizaciones de UI con limitación de velocidad muestran el texto
Toda la tubería se transmite de extremo a extremo. Sin almacenar en búfer la respuesta completa en el servidor. El primer token de Gemini llega a la pantalla del usuario en milisegundos.