¿Cómo ejecutar LLMs (IA) de código abierto en tu ordenador?
Configuré mi propio asistente de IA que se ejecuta completamente en mi ordenador. No necesita conexión a internet. No se envían datos a la nube.
Si te ha picado la curiosidad por ejecutar tu propia IA pero pensabas que requerías un título en informática, tengo buenas noticias: es más fácil de lo que crees.
¿Por qué querrías un LLM (IA) local?
Antes de entrar en el cómo, hablemos del porqué. Ejecutar LLMs (IA) localmente tiene algunas ventajas reales:
- Privacidad: Tus conversaciones nunca salen de tu ordenador. Ninguna empresa almacena, analiza o entrena con tus datos.
- No requiere internet: Una vez configurado, puedes usar tu IA en cualquier lugar: en un avión, en una cafetería con WiFi inestable o en medio de la nada.
- Es gratis: Tras la configuración inicial, no hay cuotas de suscripción ni costes de API.
- Es tuyo: Tú controlas todo. Sin límites de tasa, sin filtros de contenido, sin cambios en los términos de servicio.
Lo que necesitarás
Esto es lo que necesité para empezar (y tú necesitarás lo mismo):
- Un ordenador razonablemente moderno (Windows, Mac o Linux)
- Unos 30 minutos de tu tiempo
- Alrededor de 4-8 GB de espacio libre en disco (dependiendo del modelo que elijas)
Eso es todo. No se requiere una GPU cara, aunque si tienes una, las cosas funcionarán más rápido.
¿Qué es llama.cpp?
Antes de entrar en la instalación, déjame explicarte qué es lo que vamos a instalar realmente.
llama.cpp es un software que te permite ejecutar Modelos de Lenguaje Grandes (IA) en tu ordenador. Piénsalo como el motor que hace que todo funcione. Estos modelos son solo archivos de datos, como archivos de vídeo o música. llama.cpp es el reproductor que sabe cómo usarlos.
Es de código abierto, gratuito y se mantiene activamente. Funciona en Mac, Windows y Linux, y está diseñado para ser rápido incluso en ordenadores normales sin tarjetas gráficas sofisticadas.
Instalación
La forma más fácil de instalar llama.cpp es a través de un gestor de paquetes.
Si usas Mac o Linux
Abre tu terminal y escribe:
brew install llama.cppEsa es la instalación. En serio.
Si usas Windows
Abre PowerShell y ejecuta:
winget install llama.cppEjecutando tu primer modelo de IA
Aquí es donde se pone emocionante. No necesitas descargar archivos de modelo manualmente ni averiguar dónde colocarlos. La herramienta lo hace todo por ti.
Esto es lo que escribes para empezar a chatear con una IA:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Esto descarga y ejecuta el modelo Llama 3.2 3B desde Hugging Face.
Permíteme desglosar lo que hace en lenguaje sencillo:
llama-cliinicia la interfaz de chat-hfle indica que descargue desde Hugging Face (un repositorio de LLMs)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0es el modelo específico a usar
El identificador del modelo tiene tres partes separadas por barras y dos puntos:
bartowskies el nombre de usuario de quien subió el modelo a Hugging FaceLlama-3.2-3B-Instruct-GGUFes el nombre del repositorio que contiene el modeloQ8_0es la versión de cuantificación específica (calidad frente a tamaño)
Cuando ejecutas este comando, el modelo se descarga automáticamente (esto puede tardar unos minutos la primera vez) y luego puedes empezar a chatear. Escribe tus preguntas y la IA responde justo ahí en tu terminal.
Cómo encontrar y usar diferentes modelos
El modelo que mencioné antes (Llama 3.2) es un buen punto de partida. Es relativamente pequeño y rápido, incluso en hardware modesto. Pero hay cientos de otros modelos que puedes probar.
Encontrar modelos en Hugging Face
GGUF es el formato de archivo que utiliza llama.cpp. Los modelos en Hugging Face vienen en diferentes formatos, pero llama.cpp necesita específicamente archivos GGUF.
Ve a huggingface.co/models y busca GGUF. Busca repositorios que terminen en -GGUF en el nombre.
Cuando encuentres un modelo que quieras probar, haz clic en él y busca el nombre del repositorio. Por ejemplo, si ves bartowski/Qwen2.5-7B-Instruct-GGUF, puedes ejecutar:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Consejos para elegir modelos:
- Números más pequeños = más rápido, pero menos capaz: Un modelo de 3B es más rápido que un modelo de 7B, que es más rápido que un modelo de 13B. El número se refiere a cuántos miles de millones de parámetros tiene el modelo.
- Busca "Instruct" o "Chat" en el nombre: Estos modelos están entrenados específicamente para conversaciones.
- La parte :Q8_0: Este es el nivel de cuantificación. Q8_0 es un buen equilibrio entre calidad y tamaño. Q4_0 es más pequeño/rápido pero de calidad ligeramente inferior.
Llevándolo un paso más allá: Ejecutar un servidor de IA
Una vez que te sientas cómodo con el chat básico, puedes subir de nivel ejecutando tu IA como un servidor. Esto te permite chatear con ella desde tu navegador web y usarla con otras aplicaciones.
Ejecuta este comando:
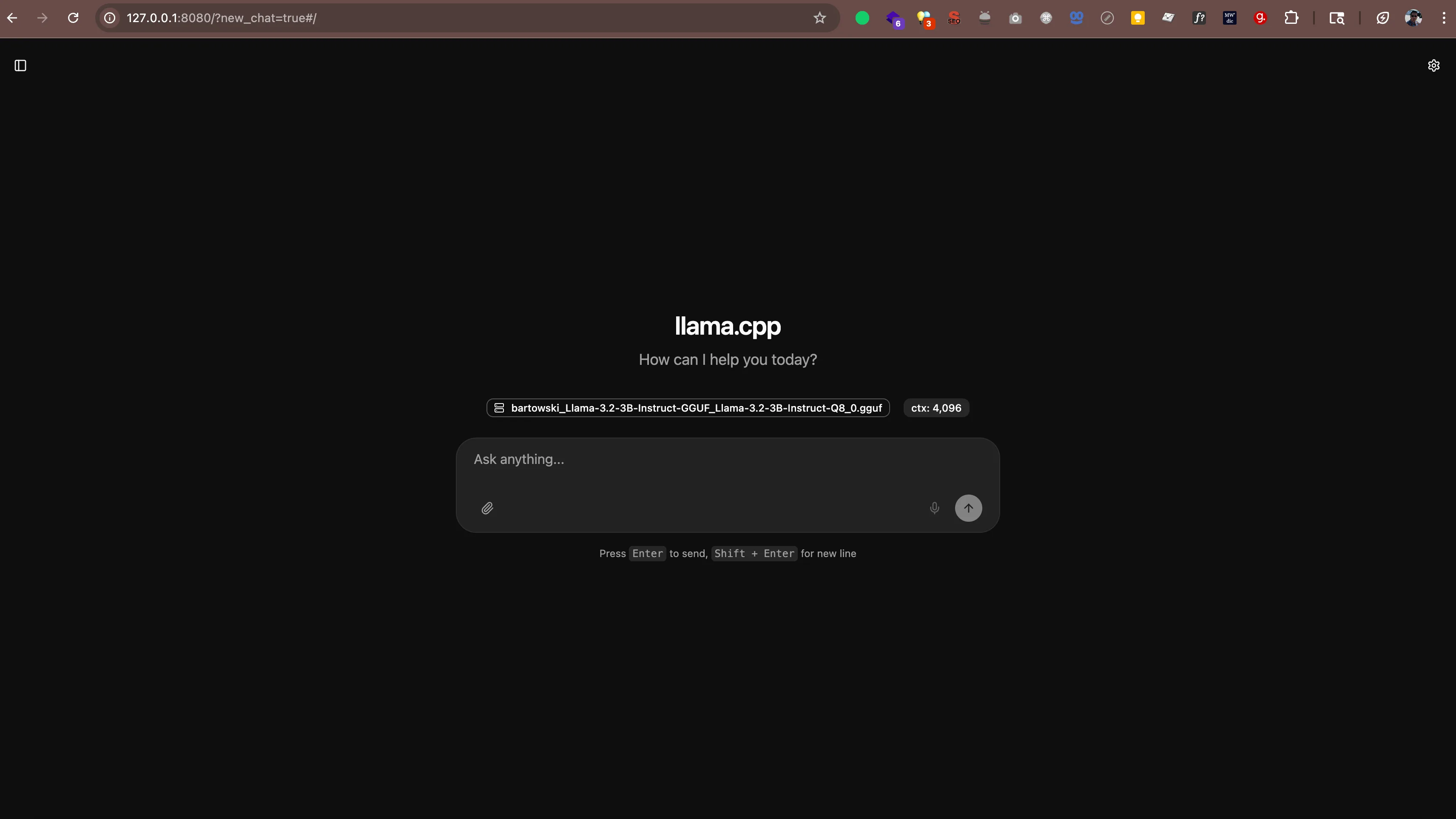
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Verás una salida como esta:
main: server is listening on http://127.0.0.1:8080 - starting the main loopAhora abre http://127.0.0.1:8080 (o http://localhost:8080) en tu navegador web. Verás una interfaz de chat donde puedes hablar con tu IA directamente desde el navegador. No se necesita software adicional.
El servidor también funciona con cualquier aplicación que admita el formato de API de OpenAI. Esto significa que puedes usar herramientas como:
- Continue.dev (asistente de codificación IA en VS Code)
- Open WebUI (una interfaz similar a ChatGPT)
- Cualquier otra aplicación que admita puntos finales de API personalizados
Dónde se almacenan los modelos
Cuando ejecutas estos comandos, los modelos se descargan automáticamente en una carpeta de caché. Por defecto, se encuentra en tu directorio de inicio bajo .cache/llama.cpp.
Si quieres cambiar dónde se almacenan los modelos, puedes establecer una variable de entorno:
# En Mac/Linux
export LLAMA_CACHE=/ruta/a/tu/cache
# En Windows (PowerShell)
$env:LLAMA_CACHE="C:\ruta\a\tu\cache"¿Qué pasa con el rendimiento?
Esto es lo que aprendí sobre el rendimiento:
- En Macs más nuevos (M1/M2/M3/M4): Los modelos funcionan sorprendentemente rápido. Los chips de la serie M tienen aceleración de IA integrada.
- En Windows/Linux con una GPU decente: También rápido. Si tienes una GPU NVIDIA, llama.cpp la usará automáticamente.
- En ordenadores más antiguos o portátiles sin GPU: ¡Sigue funcionando! Simplemente quédate con modelos más pequeños (3B o 7B) y espera respuestas más lentas.
Como referencia, en mi M4 Pro con 48 GB de RAM, un modelo de 3B genera texto a unos 60-65 tokens por segundo. Eso es lo suficientemente rápido como para sentirse como una conversación real.
llama.cpp vs Ollama vs vLLM
Puede que hayas oído hablar de otras herramientas como Ollama o vLLM. Así es como se comparan:
Ollama
Ollama está construido sobre llama.cpp. Añade una interfaz más sencilla y gestión automática de modelos, pero esa comodidad conlleva una sobrecarga de rendimiento. En mis pruebas en un Mac M4 Pro con 48 GB de RAM, llama.cpp fue un orden de magnitud más rápido que Ollama ejecutando los mismos modelos.
Si quieres el máximo rendimiento y no te importa usar la línea de comandos, quédate con llama.cpp. Si prefieres una gestión de modelos más sencilla y puedes aceptar velocidades ligeramente más lentas, Ollama funciona bien.
vLLM
vLLM no es compatible con macOS. Es solo para Linux y está diseñado para implementaciones de servidor de alto rendimiento con múltiples GPU. Si estás en un Mac, no es una opción.
Conclusión
Para los usuarios de Mac, especialmente en Apple Silicon (M1/M2/M3/M4), llama.cpp es la mejor opción. Es la opción más rápida y tiene aceleración nativa Metal. Ollama está bien si quieres una gestión más sencilla. vLLM no está disponible en Mac.
Preguntas que podrías tener
¿Es esto legal?
Sí. Los modelos en Hugging Face son de código abierto y de uso gratuito. Muchos son publicados por Meta (Facebook), Mistral AI y otras organizaciones que permiten explícitamente el uso personal y comercial.
¿Ralentizará mi ordenador?
Mientras la IA se está ejecutando, utiliza recursos de CPU/GPU. Pero cuando la cierras, todo vuelve a la normalidad. Es como ejecutar cualquier otra aplicación.
¿Puedo usar esto para trabajar?
Eso depende de las políticas de tu trabajo. Dado que todo se ejecuta localmente y tus datos no salen de tu máquina, es generalmente más seguro que la IA en la nube. Pero consulta primero con tu departamento de TI.
¿Necesito estar conectado?
Solo para la descarga inicial de modelos. Después de eso, todo funciona completamente sin conexión.
Mi experiencia
He estado usando mi IA local y estoy impresionado. No es tan capaz como GPT-5, Claude Sonnet 4.5 o Gemini 2.5, pero para muchas tareas (escribir correos electrónicos, generar ideas, responder preguntas) es más que suficiente.
Lo que más aprecio es el aspecto de la privacidad. Mis conversaciones se quedan en mi máquina. No se envían datos a servidores externos. No se introducen conjuntos de datos de entrenamiento en ningún sitio. Esto lo hace más adecuado para trabajar con información confidencial en comparación con la IA en la nube, aunque aún debes seguir las políticas de seguridad de tu organización.
¿Es perfecto? No. Las respuestas a veces pueden ser lentas si estoy ejecutando un modelo más grande. Y la calidad no está al nivel de las mejores IA en la nube. Pero ¿para un asistente gratuito, privado y siempre disponible? Acepto ese compromiso.