Añadir tu propio asistente de IA a tu sitio web sin costes empresariales
Las soluciones RAG personalizadas, como los chatbots de IA, no tienen por qué ser caras. Puedes ejecutarlas de forma gratuita utilizando el generoso nivel gratuito de Cloudflare.
Las plataformas empresariales como AWS Kendra o Azure AI Search pueden costar miles al mes, mientras que opciones como el nivel de inicio de Pinecone o soluciones autohospedadas con pgvector ofrecen alternativas más económicas. Después de participar en varios proyectos RAG, he descubierto que Cloudflare AI Search puede ser una buena opción dependiendo de tus necesidades. No se adaptará a todos los casos de uso, pero para muchos escenarios se encarga de la mayor parte del trabajo pesado.
Esta publicación explica cómo construí un chatbot para este sitio utilizando Cloudflare AI Search. Cubriré qué es RAG, cómo AI Search simplifica el flujo de trabajo, detalles de implementación (streaming, almacenamiento, limitación de velocidad) costes reales y cómo esto se escala a casos de uso empresariales.
Aunque este es un sitio personal (mi jardín digital), la misma arquitectura se aplica tanto si estás indexando un sitio web personal como documentación de empresa.
¿Qué es RAG?
RAG (Generación Aumentada por Recuperación) es un patrón que fundamenta las respuestas de los LLM en tus datos reales. En lugar de depender únicamente de los datos de entrenamiento del modelo, RAG recupera contenido relevante de tus documentos y lo incluye en el prompt.
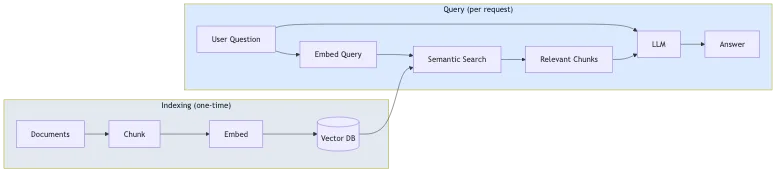
El proceso tiene dos fases:
- Indexación (una sola vez): Tus documentos se dividen en fragmentos (chunks), se convierten en incrustaciones vectoriales (vector embeddings) y se almacenan en una base de datos vectorial.
- Consulta (por solicitud): La pregunta del usuario se incrusta, se recuperan fragmentos similares mediante búsqueda semántica y el LLM genera una respuesta utilizando esos fragmentos como contexto.
Este enfoque reduce las alucinaciones porque el modelo responde basándose en tu contenido, no solo en su conocimiento general. También significa que no necesitas ajustar un modelo cada vez que cambia tu contenido.
Lo que hace realmente Cloudflare AI Search
Antes de entrar en la implementación, vale la pena entender lo que AI Search (anteriormente llamado AutoRAG) proporciona de serie:
- Indexación automática: Apúntalo a tu sitio web o fuente de datos, y rastrea e indexa tu contenido automáticamente.
- Incrustaciones vectoriales: Genera y gestiona las incrustaciones para la búsqueda semántica.
- Flujo de trabajo RAG: Recupera contenido relevante y genera respuestas utilizando ese contexto.
- Actualizaciones continuas: Cuando tu contenido cambia, el índice se actualiza automáticamente.
Esto significa que no necesitas construir la lógica de fragmentación, incrustación, almacenamiento vectorial o recuperación por ti mismo. AI Search se encarga de todo eso.
Visión general de la arquitectura
Esto es lo que construí realmente:
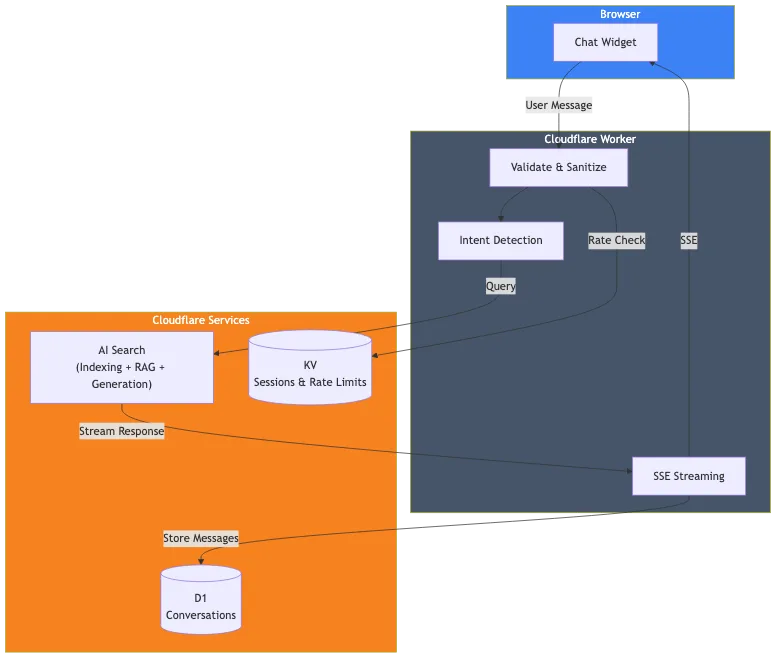
Los componentes son:
- Cloudflare AI Search: Indexa este sitio web y gestiona el flujo de trabajo RAG.
- Cloudflare Worker: Gestiona las solicitudes, la validación y el streaming de respuestas.
- Cloudflare D1: Almacena el historial de conversaciones para análisis.
- Cloudflare KV: Gestiona sesiones y limitación de velocidad.
La implementación principal
La llamada real a AI Search es sencilla. Esta es la parte clave:
// Obtener el binding de IA del contexto de Cloudflare
const ai = await getCloudflareAI();
// Llamar a AI Search
const aiSearch = ai.autorag('your-ai-search-instance');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});Eso es todo para la parte RAG. AI Search toma la consulta del usuario, busca en el contenido indexado de mi sitio web, recupera los fragmentos relevantes y genera una respuesta utilizando ese contexto.
Configuración de AI Search
Para usar AI Search, necesitas:
- Crear una instancia de AI Search en el panel de Cloudflare.
- Conectar tu fuente de datos (en mi caso, este sitio web).
- Esperar a que se complete la indexación inicial.
- Añadir el binding de IA a tu wrangler.toml.
# wrangler.toml
[ai]
binding = "AI"Una vez configurado, AI Search supervisa continuamente tu fuente de datos y actualiza el índice cuando el contenido cambia.
El prompt del sistema
El prompt del sistema define cómo debe comportarse la IA. Aquí es donde das forma a la personalidad y los límites del chatbot:
function getSystemPrompt(locale: string): string {
return `Eres un asistente de IA útil en el sitio web de portafolio de David Loor.
## REGLAS CRÍTICAS:
1. SIEMPRE responde en ${languageNames[locale]}
2. SOLO responde preguntas sobre David Loor; NO eres un asistente de propósito general
3. Utiliza el contexto proporcionado sobre David; no inventes información
## Tu Comportamiento:
- Sé útil y profesional
- Mantén las respuestas concisas (máximo 2-3 párrafos)
- Cuando sea apropiado, menciona que pueden reservar una llamada o enviar un correo electrónico
- No hables de precios; sugiere que lo discutan directamente
- No finjas ser David; eres su asistente de IA`;
}La sección de reglas críticas es importante. Sin límites explícitos, el chatbot intentará responder preguntas de conocimiento general, que no es lo que quiero para un asistente de portafolio.
Streaming de respuestas
Nadie quiere esperar a una respuesta completa para ver algo. AI Search admite el streaming de serie con stream: true. Puedes canalizar la respuesta directamente al cliente utilizando Server-Sent Events (SSE), lo que proporciona a los usuarios ese efecto de escritura familiar al estilo ChatGPT.
Almacenar conversaciones con D1
Si quieres analizar conversaciones o mejorar tu chatbot con el tiempo, puedes almacenarlas en Cloudflare D1 (su SQLite sin servidor). Simplemente ejecuta las escrituras de la base de datos en segundo plano para que no bloqueen la respuesta en streaming.
Limitación de velocidad con KV
Las API públicas necesitan protección. Utilizo Cloudflare KV para una limitación de velocidad sencilla:
const RATE_LIMIT_WINDOW_MS = 60000; // 1 minuto
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 mensajes por minuto
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// Nueva ventana
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Límite de velocidad alcanzado
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}Desarrollo local
Para el desarrollo local, utilizo npx wrangler dev, que ejecuta el Worker localmente mientras se conecta a mis servicios de Cloudflare en producción (AI Search, D1, KV). Esto me proporciona un entorno similar a la producción sin necesidad de desplegar:
npx wrangler devEl código del Worker se ejecuta en mi máquina, pero los bindings se conectan a los servicios remotos reales. Esto significa que el desarrollo local sí consume tu cuota de neuronas, pero es la forma más precisa de probar antes de desplegar.
¿Cuánto me costó esto?
Aquí están las buenas noticias: puedes ejecutar toda esta pila en el nivel gratuito de Cloudflare. No se requiere ningún plan de pago.
| Servicio | Límites del Nivel Gratuito |
|---|---|
| AI Search | Disponible en todos los planes (incluido el gratuito) |
| Workers AI | 10.000 neuronas/día |
| D1 | 5M lecturas/día, 100K escrituras/día, 5GB de almacenamiento |
| KV | 100K lecturas/día, 1K escrituras/día, 1GB de almacenamiento |
| Workers | 100K solicitudes/día |
El límite principal que alcanzarás son las neuronas de Workers AI. Hagamos los cálculos.
Workers AI (el coste principal)
Obtienes 10.000 neuronas gratuitas al día (unas 300.000 al mes). Una interacción de chat típica con AI Search utiliza aproximadamente entre 500 y 1.000 neuronas, dependiendo de la longitud de la respuesta. Eso significa:
- ~300-600 mensajes de chat por día antes de superar el nivel gratuito
- ~9.000-18.000 mensajes al mes incluidos
Para la mayoría de los sitios personales y pequeñas empresas, esto es más que suficiente para funcionar de forma totalmente gratuita. Más allá de eso, pagas 0,011 $ por cada 1.000 neuronas. Un chatbot concurrido que gestione 1.000 mensajes/día costaría aproximadamente entre 5 y 10 $ adicionales al mes.
Otros servicios (límites generosos)
Los otros límites del nivel gratuito son generosos:
- Solicitudes de Workers: 100K/día. Eso son ~100K mensajes de chat diarios antes de alcanzar los límites.
- Lecturas de D1: 5M/día. Cada chat utiliza unas pocas lecturas, por lo que miles de chats diarios.
- Escrituras de D1: 100K/día. Cada mensaje almacena 2 filas, por lo que ~50K mensajes/día.
- Lecturas de KV: 100K/día. La limitación de velocidad utiliza ~2 lecturas por mensaje.
Para la mayoría de los sitios, las neuronas de Workers AI son el único límite que probablemente te acerques. Los otros servicios tienen límites diarios que se reinician, lo que te da mucho margen.
Lo que no construí
Vale la pena señalar lo que AI Search manejó por mí:
- Fragmentación de documentos: No escribí ninguna lógica de fragmentación.
- Generación de incrustaciones: AI Search genera y gestiona las incrustaciones.
- Almacenamiento vectorial: No es necesario configurar Vectorize por separado.
- Lógica de recuperación: AI Search gestiona la búsqueda semántica.
- Actualizaciones de índice: Los cambios de contenido se detectan automáticamente.
Si hubiera construido esto desde cero con incrustaciones separadas, base de datos vectorial y flujo de trabajo de recuperación, habría sido significativamente más trabajo. AI Search abstrae todo eso.
Escalado a casos de uso empresariales
Aunque construí esto para mi sitio personal, el mismo patrón se aplica a escenarios empresariales. AI Search admite diferentes fuentes de datos más allá de los sitios web:
Soporte al cliente
Apunta AI Search a tu sitio de documentación, centro de ayuda o base de conocimientos. El chatbot puede responder preguntas sobre productos, consultas de solución de problemas y políticas sin entrenar un modelo personalizado. Añade lógica para escalar a agentes humanos cuando sea necesario.
Asistente de conocimiento interno
Indexa tu wiki corporativa, Confluence o documentación interna. Los empleados pueden hacer preguntas en lenguaje natural en lugar de buscar en carpetas. El prompt del sistema define los límites de acceso y el estilo de respuesta.
Asesor de productos de comercio electrónico
Indexa tus páginas de catálogo de productos. Los clientes pueden preguntar "qué portátil es bueno para la edición de vídeo por menos de 1000 $" y obtener respuestas basadas en tu inventario real. Dirige a los clientes listos para comprar al pago.
Qué cambia al escalar
La arquitectura central se mantiene igual. Lo que cambia:
- Fuente de datos: En lugar de un sitio web personal, conectas el contenido de tu empresa.
- Prompt del sistema: Adaptado a la voz de tu marca y caso de uso.
- Lógica empresarial: Enrutamiento personalizado basado en las necesidades del usuario.
- Límites de velocidad: Ajustados según el tráfico esperado.
- Autenticación: Añadir autenticación de usuario si se indexa contenido privado.
AI Search gestiona la complejidad de RAG independientemente de si estás indexando 50 páginas o 50.000.
Flexibilidad del modelo
AI Search no está limitado a un único modelo. Tienes opciones:
Modelos de generación: AI Search admite modelos de varios proveedores, incluidos Anthropic (Claude 3.5, Claude 4), Google (Gemini 2.5 Flash/Pro), OpenAI (GPT-4o, GPT-5), además de Cerebras, Grok, Groq y Workers AI. Puedes seleccionar una Opción Inteligente por Defecto que Cloudflare actualiza automáticamente, o elegir un modelo específico. Los modelos de generación incluso se pueden anular por solicitud a través de la API.
Modelos de incrustación: Las opciones incluyen los modelos text-embedding-3 de OpenAI, Gemini Embedding de Google y los modelos BGE de Workers AI. El modelo de incrustación se establece durante la configuración inicial y no se puede cambiar más tarde (requeriría volver a indexar todo).
Trae tu propio modelo: Si los modelos admitidos no satisfacen tus necesidades, puedes traer tu propio modelo de generación a través de AI Gateway o utilizando AI Search solo para la recuperación y enviando los resultados a cualquier LLM externo.
Limitaciones
Este enfoque tiene algunas restricciones:
- Específico de Cloudflare: AI Search solo funciona dentro del ecosistema de Cloudflare.
- Ajuste limitado de la recuperación: Puedes ajustar el tamaño y solapamiento de los fragmentos, pero no la estrategia de fragmentación subyacente ni el algoritmo de recuperación.
- Fuentes de datos limitadas: AI Search admite sitios web y almacenamiento R2 (para PDFs, documentos, etc.), pero no bases de datos o API arbitrarias directamente.
Para casos de uso más complejos (fragmentación personalizada, múltiples fuentes de datos heterogéneas o recuperación especializada), tendrías que construir más del flujo de trabajo tú mismo utilizando Vectorize y Workers AI directamente.
Prueba el chatbot en la esquina de esta página. Está ejecutando exactamente lo que describí aquí.
Si estás construyendo algo similar y quieres discutir los detalles, hablemos.