Warum ich Server-Sent Events gegenüber WebSockets für das Streaming von KI-Antworten gewählt habe
Als ich Kindle-ChatGPT baute, musste ich KI-Antworten in Echtzeit an den Client streamen. Sie kennen doch dieses befriedigende Gefühl, wenn ChatGPT seine Antwort Wort für Wort eintippt? Genau dieses Gefühl wollte ich nachbilden.
Mein erster Gedanke war, auf WebSockets zurückzugreifen. Das ist doch die Standardlösung für Echtzeitkommunikation, oder? Aber nach etwas Recherche stellte ich fest, dass es eine einfachere, elegantere Lösung gab, die direkt vor meinen Augen lag: Server-Sent Events (SSE).
Was sind Server-Sent Events?
Server-Sent Events ist ein Standard, der es Servern ermöglicht, Daten über eine einzige HTTP-Verbindung an Clients zu senden. Im Gegensatz zu WebSockets ist SSE unidirektional: Der Server sendet Daten an den Client, aber nicht umgekehrt.
Das Protokoll ist überraschend einfach. Der Server antwortet mit Content-Type: text/event-stream und sendet Daten in diesem Format:
data: Hallo
data: Welt
data: {"message": "JSON funktioniert auch"}
Jede Nachricht beginnt mit data: und wird durch zwei Newlines getrennt. Das war's schon. Keine Handshakes, kein Frame-Parsing, keine Verbindungs-Upgrades.
Warum SSE statt WebSockets?
Der Punkt bei der Streamings von KI-Antworten ist: Der Client sendet eine Frage, und der Server streamt die Antwort zurück. Das ist fundamental ein Einwegfluss. Warum sollte ich eine bidirektionale Kommunikation einrichten, wenn ich Daten nur in eine Richtung benötige?
WebSockets würden funktionieren, bringen aber Overhead mit sich:
- Verbindungs-Upgrade: WebSockets erfordern einen HTTP-Upgrade-Handshake
- Verwaltung persistenter Verbindungen: Sie müssen Wiederverbindungslogik, Heartbeats und den Verbindungsstatus verwalten
- Infrastrukturkomplexität: Einige Proxys und CDNs kommen mit WebSockets nicht gut zurecht
- Mehr Code: Sowohl Client als auch Server benötigen komplexere Implementierungen
SSE hingegen:
- Nutzt Standard-HTTP: Funktioniert durch jeden Proxy, CDN oder Load Balancer, der HTTP verarbeitet
- Eingebaute Wiederverbindung: Die
EventSourceAPI des Browsers stellt automatisch eine Verbindung wieder her - Einfaches Protokoll: Nur Text über HTTP
- Native Browser-Unterstützung: Keine Bibliotheken auf Client-Seite erforderlich
Für meinen Anwendungsfall, das Streamen von Text aus einem KI-Modell, war SSE die offensichtliche Wahl.
Wie die Gemini API SSE verwendet
Etwas, das mir anfangs nicht bewusst war: Googles Gemini API unterstützt SSE nativ für das Streamen von Antworten. Man muss nur ?alt=sse an den Endpunkt anhängen:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
Die API gibt einen Stream von Events zurück, die jeweils einen Teil der Antwort enthalten:
data: {"candidates":[{"content":{"parts":[{"text":"Hallo"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" dort"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":"!"}],"role":"model"}}]}
Erstellen eines Streaming-Proxys mit TransformStream
Mein Server fungiert als Proxy zwischen dem Client und Gemini. Aber ich wollte das rohe SSE-Format von Gemini nicht direkt an den Client weiterleiten. Die verschachtelte JSON-Struktur (candidates[0].content.parts[0].text) ist für meine einfache Chat-Oberfläche unnötig kompliziert.
Stattdessen verwendete ich einen TransformStream, um die SSE-Events zu parsen und nur den Text zu extrahieren:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Unvollständige Zeile im Puffer behalten
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Fehler beim Parsen elegant behandeln
}
}
}
},
flush(controller) {
// Verbleibende Daten im Puffer verarbeiten
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Fehler beim finalen Parsen behandeln
}
}
}
});
Es gibt ein subtiles, aber wichtiges Detail: SSE-Events können über Netzwerk-Chunks aufgeteilt werden. Eine einzelne data:-Zeile könnte in zwei Teilen ankommen. Der Puffer löst dies, indem er unvollständige Zeilen behält, bis der nächste Chunk eintrifft.
Die Client-seitige Implementierung
Auf der Client-Seite hätte ich die native EventSource API verwenden können. Da mein transformierter Stream jedoch reinen Text sendet (nicht im SSE-Format), habe ich direkt die ReadableStream API verwendet:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// UI mit der gesamten Nachricht aktualisieren
setMessage(fullMessage);
}
Das ist die Schönheit des Streamings: Jeder Chunk kommt an, sobald die KI ihn generiert, und wir können die UI sofort aktualisieren.
Optimierung für E-Ink-Displays
Hier wurde mein spezifischer Anwendungsfall interessant. Kindle E-Ink-Displays haben langsame Aktualisierungsraten. Wenn ich die UI bei jedem einzelnen Chunk aktualisiert hätte, hätte der Bildschirm ständig geflackert und wäre mit der Aktualisierung überfordert gewesen.
Die Lösung waren gedrosselte (throttled) Aktualisierungen:
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Alle 500 ms aktualisieren
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Immer mit dem finalen Inhalt aktualisieren
setMessage(fullMessage);
Dies bündelt UI-Aktualisierungen in 500-ms-Intervallen, während weiterhin Daten so schnell wie möglich empfangen werden. Der Text sammelt sich im Speicher an, und die Anzeige wird in einem Tempo aktualisiert, das der E-Ink-Bildschirm bewältigen kann.
Fehlerbehandlung und Randfälle
Produktionscode muss mehrere Randfälle berücksichtigen:
1. Netzwerkfehler mitten im Stream
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Chunk verarbeiten
}
} catch (error) {
// Netzwerkfehler ist aufgetreten
// Teilnachricht + Fehleranzeige anzeigen
setMessage(fullMessage + '\n\n[Verbindung unterbrochen]');
}
2. Fehlerhaftes JSON von der API
Der Try-Catch-Block im TransformStream stellt sicher, dass ein fehlerhafter Chunk nicht den gesamten Stream unterbricht. Wir protokollieren den Fehler und fahren mit der Verarbeitung fort.
3. Leere Antworten
Manchmal gibt die API Chunks ohne Textinhalt zurück. Die optionale Verkettung (?.) behandelt dies elegant.
Wann SSE vs. WebSockets verwenden?
Nach dieser Erfahrung sieht mein mentales Modell wie folgt aus:
SSE verwenden, wenn:
- Daten hauptsächlich vom Server zum Client fließen
- Sie eine einfache Implementierung mit minimaler Infrastruktur benötigen
- Automatische Wiederverbindung wertvoll ist
- Sie Text, Protokolle, Benachrichtigungen oder Events streamen
WebSockets verwenden, wenn:
- Sie bidirektionale Kommunikation benötigen
- Geringe Latenz entscheidend ist (Gaming, kollaboratives Bearbeiten)
- Sie Binärdaten senden
- Sie häufig Nachrichten vom Client an den Server senden müssen
Für KI-Chat-Anwendungen trifft SSE den idealen Punkt. Der Benutzer sendet eine Nachricht (regulärer POST-Request), und die KI streamt die Antwort zurück (SSE). Einfach, effizient und es funktioniert überall.
Bereitstellungsüberlegungen
Ich habe dies auf Cloudflare Workers bereitgestellt, und SSE funktionierte ohne spezielle Konfiguration. Die Workers-Laufzeitumgebung unterstützt das native Streamen von Antworten:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Ein paar Dinge sind hier zu beachten:
- Kein Caching: Streaming-Antworten sollten niemals gecacht werden
- Keep-alive: Hilft, die Verbindung für längere Streams aufrechtzuerhalten
- Content-Type: Ich habe
text/plainverwendet, da ich reinen Text sende, nicht das SSE-Format
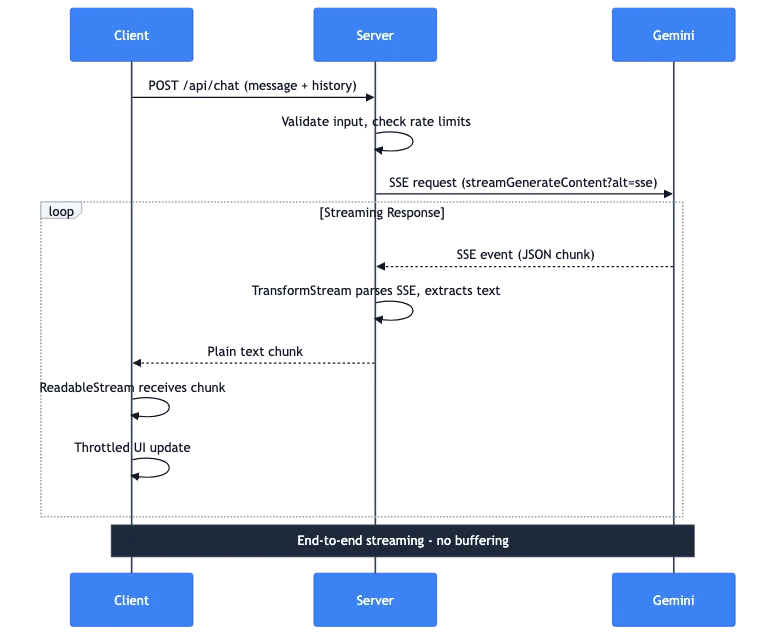
Der vollständige Datenfluss
Lassen Sie mich durchgehen, was passiert, wenn ein Benutzer eine Nachricht sendet:
- Client: POST-Anfrage mit Nachricht und Konversationsverlauf
- Server: Validiert Eingaben, prüft Ratenbegrenzungen
- Server: Führt eine SSE-Anfrage an die Gemini API durch
- Gemini: Streamt SSE-Events mit JSON-Chunks zurück
- Server: TransformStream parst SSE, extrahiert Text
- Server: Leitet reine Text-Chunks an den Client weiter
- Client: ReadableStream empfängt Chunks
- Client: Gedrosselte UI-Updates zeigen den Text an
Die gesamte Pipeline streamt Ende-zu-Ende. Die vollständige Antwort wird nicht auf dem Server gepuffert. Das erste Token von Gemini erreicht den Bildschirm des Benutzers innerhalb von Millisekunden.