Waarom ik koos voor Server-Sent Events boven WebSockets voor het streamen van AI-antwoorden
Toen ik Kindle-ChatGPT bouwde, moest ik AI-antwoorden in realtime naar de client streamen. Je kent dat bevredigende gevoel wel dat je ChatGPT je antwoord woord voor woord ziet typen? Datzelfde gevoel wilde ik nabootsen.
Mijn eerste ingeving was om WebSockets te gebruiken. Dat is toch dé oplossing voor realtime communicatie? Maar na wat onderzoek realiseerde ik me dat er een eenvoudigere, elegantere oplossing in het volle zicht lag: Server-Sent Events (SSE).
Wat zijn Server-Sent Events?
Server-Sent Events is een standaard waarmee servers gegevens via één enkele HTTP-verbinding naar clients kunnen pushen. In tegenstelling tot WebSockets is SSE unidirectioneel: de server stuurt gegevens naar de client, maar niet andersom.
Het protocol is verrassend eenvoudig. De server antwoordt met Content-Type: text/event-stream en stuurt gegevens in dit formaat:
data: Hallo
data: Wereld
data: {"message": "JSON werkt ook"}
Elk bericht begint met data: en wordt gescheiden door twee nieuwe regels. Dat is alles. Geen handshakes, geen frame-parsing, geen connection upgrades.
Waarom SSE in plaats van WebSockets?
Het punt bij het streamen van AI-antwoorden is dit: de client stuurt een vraag, en de server streamt het antwoord terug. Het is fundamenteel een eenrichtingsverkeer. Waarom zou ik een bidirectionele communicatie opzetten als ik maar één kant op gegevens nodig heb?
WebSockets zouden werken, maar ze brengen overhead met zich mee:
- Connection upgrade: WebSockets vereisen een HTTP upgrade handshake
- Persistent connection management: Je moet logica voor opnieuw verbinden, heartbeats en verbindingsstatus beheren
- Infrastructuurcomplexiteit: Sommige proxies en CDNs werken niet goed met WebSockets
- Meer code: Zowel client als server hebben complexere implementaties nodig
SSE daarentegen:
- Gebruikt standaard HTTP: Werkt via elke proxy, CDN of load balancer die HTTP aankan
- Ingebouwde herverbinding: De
EventSourceAPI van de browser maakt automatisch opnieuw verbinding - Eenvoudig protocol: Gewoon tekst via HTTP
- Native browserondersteuning: Geen bibliotheken nodig aan de clientzijde
Voor mijn gebruikssituatie, het streamen van tekst van een AI-model, was SSE de voor de hand liggende keuze.
Hoe de Gemini API SSE gebruikt
Iets wat ik aanvankelijk niet wist: de Gemini API van Google ondersteunt native SSE voor het streamen van antwoorden. Je hoeft alleen maar ?alt=sse toe te voegen aan het endpoint:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
De API retourneert een stroom van gebeurtenissen, die elk een stukje van het antwoord bevatten:
data: {"candidates":[{"content":{"parts":[{"text":"Hallo"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" daar"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":"!"}],"role":"model"}}]}
Een streaming proxy bouwen met TransformStream
Mijn server fungeert als een proxy tussen de client en Gemini. Maar ik wilde de ruwe SSE-indeling van Gemini niet doorsturen naar de client. De geneste JSON-structuur (candidates[0].content.parts[0].text) is onnodig complex voor mijn eenvoudige chatinterface.
In plaats daarvan gebruikte ik een TransformStream om de SSE-gebeurtenissen te parsen en alleen de tekst te extraheren:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Onvolledige regel in buffer houden
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Foutafhandeling bij parsen
}
}
}
},
flush(controller) {
// Eventuele resterende gegevens in de buffer verwerken
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Afhandelingsfouten bij parsen
}
}
}
});
Er is een subtiel maar belangrijk detail: SSE-gebeurtenissen kunnen over netwerk-chunks worden verdeeld. Eén enkele data: regel kan in twee stukken aankomen. De buffer lost dit op door onvolledige regels vast te houden totdat de volgende chunk arriveert.
De client-side implementatie
Aan de clientzijde kon ik de native EventSource API gebruiken. Maar aangezien mijn getransformeerde stream platte tekst stuurt (geen SSE-indeling), gebruikte ik direct de ReadableStream API:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// De UI bijwerken met het geaccumuleerde bericht
setMessage(fullMessage);
}
Dit is de schoonheid van streaming: elke chunk komt binnen zodra de AI deze genereert, en we kunnen de UI onmiddellijk bijwerken.
Optimaliseren voor e-ink displays
Hier werd mijn specifieke gebruikssituatie interessant. Kindle e-ink displays hebben trage verversingsfrequenties. Als ik de UI bij elke chunk zou bijwerken, zou het scherm constant flikkeren en moeite hebben om bij te blijven.
De oplossing was throttled updates (afgetaste updates):
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Elke 500ms bijwerken
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Altijd bijwerken met de uiteindelijke inhoud
setMessage(fullMessage);
Dit bundelt UI-updates in intervallen van 500 ms, terwijl de gegevens nog steeds binnenkomen zodra ze beschikbaar zijn. De tekst wordt in het geheugen opgebouwd en het scherm wordt bijgewerkt in een tempo dat het e-ink scherm aankan.
Foutafhandeling en randgevallen
Productiecode moet verschillende randgevallen afhandelen:
1. Netwerkfouten midden in de stroom
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Chunk verwerken
}
} catch (error) {
// Netwerkfout opgetreden
// Gedeeltelijk bericht + foutindicator tonen
setMessage(fullMessage + '\n\n[Verbinding onderbroken]');
}
2. Incorrecte JSON van de API
De try-catch in de TransformStream zorgt ervoor dat één slechte chunk de hele stroom niet breekt. We loggen de fout en gaan door met verwerken.
3. Lege antwoorden
Soms retourneert de API chunks zonder tekstinhoud. De optionele chaining (?.) handelt dit elegant af.
Wanneer SSE versus WebSockets gebruiken
Na deze ervaring is dit mijn denkwijze:
Gebruik SSE wanneer:
- Gegevens voornamelijk van server naar client stromen
- Je een eenvoudige implementatie met minimale infrastructuur nodig hebt
- Automatische herverbinding waardevol is
- Je tekst, logs, meldingen of gebeurtenissen streamt
Gebruik WebSockets wanneer:
- Je bidirectionele communicatie nodig hebt
- Lage latentie cruciaal is (gaming, gezamenlijke bewerking)
- Je binaire gegevens verzendt
- Je vaak berichten van client naar server moet sturen
Voor AI-chattoepassingen is SSE de perfecte middenweg. De gebruiker stuurt een bericht (gewone POST-aanvraag) en de AI streamt het antwoord terug (SSE). Eenvoudig, efficiënt en het werkt overal.
Implementatieoverwegingen
Ik heb dit geïmplementeerd op Cloudflare Workers, en SSE werkte zonder speciale configuratie. De Workers runtime ondersteunt native streaming van antwoorden:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Een paar dingen om op te merken:
- Geen caching: Streaming antwoorden mogen nooit worden gecachet
- Keep-alive: Helpt de verbinding te behouden voor langere streams
- Content-Type: Ik gebruikte
text/plainomdat ik ruwe tekst stuur, geen SSE-indeling
De volledige gegevensstroom
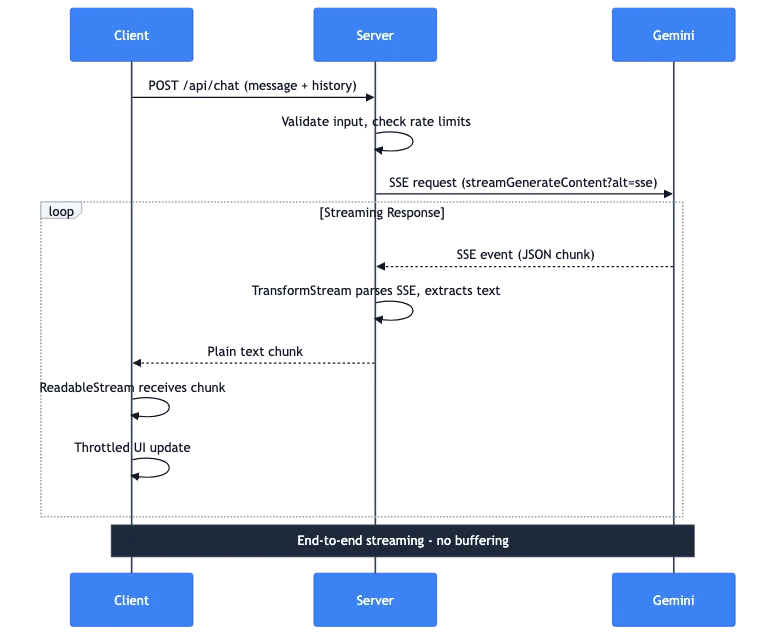
Ik zal doorlopen wat er gebeurt wanneer een gebruiker een bericht stuurt:
- Client: POST-verzoek met bericht en gespreksgeschiedenis
- Server: Valideert invoer, controleert snelheidslimieten
- Server: Voert SSE-verzoek uit naar Gemini API
- Gemini: Streamt SSE-gebeurtenissen met JSON-chunks terug
- Server: TransformStream parseert SSE, extraheert tekst
- Server: Stuurt platte tekst-chunks door naar client
- Client: ReadableStream ontvangt chunks
- Client: Afgetaste UI-updates tonen de tekst
De hele pijplijn streamt end-to-end. Het volledige antwoord wordt niet op de server gebufferd. Het eerste token van Gemini bereikt het scherm van de gebruiker binnen milliseconden.