Hoe u open source LLM's (AI) op uw computer kunt uitvoeren?
Ik heb mijn eigen AI-assistent ingesteld die volledig op mijn computer draait. Geen internetverbinding nodig. Geen gegevens naar de cloud verzonden.
Als je nieuwsgierig bent naar het draaien van je eigen AI, maar dacht dat je daarvoor een diploma in informatica nodig had, dan heb ik goed nieuws: het is eenvoudiger dan je denkt.
Waarom zou je een lokale LLM (AI) willen?
Voordat we in het hoe duiken, laten we het hebben over het waarom. Het lokaal draaien van LLM's (AI) heeft een aantal echte voordelen:
- Privacy: Je gesprekken verlaten nooit je computer. Geen enkel bedrijf slaat je gegevens op, analyseert ze of traint ermee.
- Geen internet vereist: Eenmaal ingesteld, kun je je AI overal gebruiken: in het vliegtuig, in een café met wisselvallige wifi, of midden in nergens.
- Het is gratis: Na de initiële installatie zijn er geen abonnementskosten of API-kosten.
- Het is van jou: Jij beheert alles. Geen snelheidslimieten, geen inhoudsfilters, geen wijzigingen in de servicevoorwaarden.
Wat je nodig hebt
Dit is wat ik nodig had om te beginnen (en jij hebt hetzelfde nodig):
- Een redelijk moderne computer (Windows, Mac of Linux)
- Ongeveer 30 minuten van je tijd
- Ongeveer 4-8 GB vrije schijfruimte (afhankelijk van het model dat je kiest)
Dat is alles. Geen dure GPU vereist, hoewel het sneller zal werken als je er wel een hebt.
Wat is llama.cpp?
Voordat we in de installatie duiken, leg ik uit wat we eigenlijk installeren.
llama.cpp is software waarmee je Large Language Models (AI) op je computer kunt draaien. Zie het als de motor die alles laat werken. Deze modellen zijn slechts gegevensbestanden, zoals video- of muziekbestanden. llama.cpp is de speler die weet hoe hij ze moet gebruiken.
Het is open source, gratis en wordt actief onderhouden. Het werkt op Mac, Windows en Linux, en is ontworpen om snel te zijn, zelfs op gewone computers zonder mooie grafische kaarten.
Installatie
De eenvoudigste manier om llama.cpp te installeren is via een pakketbeheerder.
Als je op een Mac of Linux zit
Open je terminal en typ:
brew install llama.cppDat is de installatie. Serieus.
Als je op Windows zit
Open PowerShell en voer uit:
winget install llama.cppJe eerste AI-model uitvoeren
Dit is waar het spannend wordt. Je hoeft modelbestanden niet handmatig te downloaden of uit te zoeken waar je ze moet plaatsen. De tool doet het allemaal voor je.
Dit typ je om te beginnen met chatten met een AI:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Dit downloadt en voert het Llama 3.2 3B-model van Hugging Face uit.
Ik zal in begrijpelijke taal uitleggen wat dit doet:
llama-clistart de chatinterface-hfgeeft aan dat het moet downloaden van Hugging Face (een repository van LLM's)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0is het specifieke model dat gebruikt moet worden
De model-ID bestaat uit drie delen, gescheiden door schuine strepen en een dubbele punt:
bartowskiis de gebruikersnaam van degene die het model op Hugging Face heeft geüploadLlama-3.2-3B-Instruct-GGUFis de naam van de repository die het model bevatQ8_0is de specifieke kwantisatieversie (kwaliteit versus grootte)
Wanneer je dit commando uitvoert, wordt het model automatisch gedownload (dit kan de eerste keer een paar minuten duren) en kun je beginnen met chatten. Typ je vragen en de AI antwoordt direct in je terminal.
Hoe je verschillende modellen vindt en gebruikt
Het model dat ik hierboven noemde (Llama 3.2) is een goed startpunt. Het is relatief klein en snel, zelfs op bescheiden hardware. Maar er zijn honderden andere modellen die je kunt proberen.
Modellen vinden op Hugging Face
GGUF is het bestandsformaat dat llama.cpp gebruikt. Modellen op Hugging Face komen in verschillende formaten, maar llama.cpp heeft specifiek GGUF-bestanden nodig.
Ga naar huggingface.co/models en zoek naar GGUF. Zoek naar repositories waarvan de naam eindigt op -GGUF.
Wanneer je een model vindt dat je wilt proberen, klik erop en zoek naar de repositorynaam. Als je bijvoorbeeld bartowski/Qwen2.5-7B-Instruct-GGUF ziet, kun je het volgende uitvoeren:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Tips voor het kiezen van modellen:
- Kleinere getallen = sneller, maar minder capabel: Een 3B-model is sneller dan een 7B-model, wat sneller is dan een 13B-model. Het getal verwijst naar het aantal miljarden parameters dat het model heeft.
- Zoek naar "Instruct" of "Chat" in de naam: Deze modellen zijn specifiek getraind voor conversaties.
- Het :Q8_0 deel: Dit is het kwantiseringsniveau. Q8_0 is een goede balans tussen kwaliteit en grootte. Q4_0 is kleiner/sneller maar iets lagere kwaliteit.
Een stap verder: Een AI-server uitvoeren
Zodra je vertrouwd bent met de basischat, kun je een niveau hoger gaan door je AI als server uit te voeren. Hiermee kun je ermee chatten vanuit je webbrowser en het gebruiken met andere apps.
Voer dit commando uit:
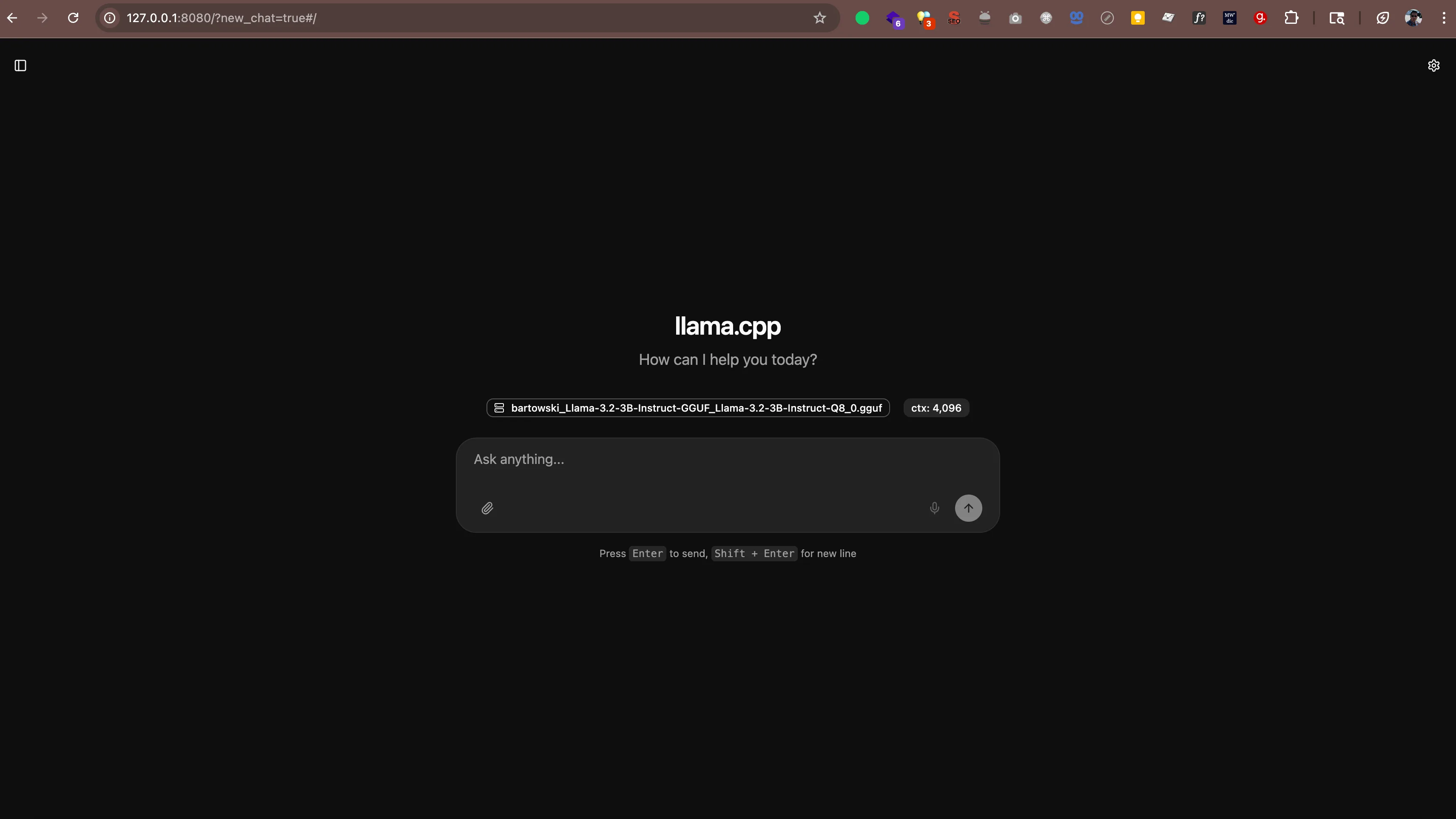
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Je ziet uitvoer zoals:
main: server is listening on http://127.0.0.1:8080 - starting the main loopOpen nu http://127.0.0.1:8080 (of http://localhost:8080) in je webbrowser. Je ziet een chatinterface waar je direct vanuit de browser met je AI kunt praten. Geen extra software nodig.
De server werkt ook met elke app die het API-formaat van OpenAI ondersteunt. Dit betekent dat je tools kunt gebruiken zoals:
- Continue.dev (AI-codeerassistent in VS Code)
- Open WebUI (een ChatGPT-achtige interface)
- Elke andere app die aangepaste API-endpoints ondersteunt
Waar de modellen worden opgeslagen
Wanneer je deze commando's uitvoert, worden modellen automatisch gedownload naar een cachemap. Standaard bevindt deze zich in je thuismap onder .cache/llama.cpp.
Als je wilt wijzigen waar modellen worden opgeslagen, kun je een omgevingsvariabele instellen:
# Op Mac/Linux
export LLAMA_CACHE=/pad/naar/jouw/cache
# Op Windows (PowerShell)
$env:LLAMA_CACHE="C:\pad\naar\jouw\cache"Hoe zit het met de prestaties?
Dit is wat ik heb geleerd over de prestaties:
- Op nieuwere Macs (M1/M2/M3/M4): Modellen draaien verrassend snel. De M-serie chips hebben ingebouwde AI-versnelling.
- Op Windows/Linux met een behoorlijke GPU: Ook snel. Als je een NVIDIA GPU hebt, gebruikt llama.cpp deze automatisch.
- Op oudere computers of laptops zonder GPU's: Werkt nog steeds! Houd je gewoon aan kleinere modellen (3B of 7B) en verwacht langzamere antwoorden.
Ter referentie: op mijn M4 Pro met 48 GB RAM genereert een 3B-model tekst met ongeveer 60-65 tokens per seconde. Dat is snel genoeg om aan te voelen als een echt gesprek.
llama.cpp versus Ollama versus vLLM
Je hebt misschien gehoord van andere tools zoals Ollama of vLLM. Dit is hoe ze zich verhouden:
Ollama
Ollama is gebouwd bovenop llama.cpp. Het voegt een eenvoudigere interface en automatisch modelbeheer toe, maar dat gemak gaat gepaard met een prestatieverlies. In mijn tests op een M4 Pro Mac met 48 GB RAM was llama.cpp een orde van grootte sneller dan Ollama die dezelfde modellen draaide.
Als je maximale prestaties wilt en het niet erg vindt om de opdrachtregel te gebruiken, blijf dan bij llama.cpp. Als je de voorkeur geeft aan eenvoudiger modelbeheer en iets langzamere snelheden kunt accepteren, werkt Ollama goed.
vLLM
vLLM ondersteunt macOS niet. Het is alleen voor Linux en ontworpen voor serverimplementaties met hoge doorvoer en meerdere GPU's. Als je op een Mac zit, is het geen optie.
Kortom
Voor Mac-gebruikers, vooral op Apple Silicon (M1/M2/M3/M4), is llama.cpp de beste keuze. Het is de snelste optie en heeft native Metal-versnelling. Ollama is prima als je eenvoudiger beheer wilt. vLLM is niet beschikbaar op Mac.
Vragen die je misschien hebt
Is dit legaal?
Ja. De modellen op Hugging Face zijn open source en gratis te gebruiken. Velen zijn gepubliceerd door Meta (Facebook), Mistral AI en andere organisaties die expliciet persoonlijk en commercieel gebruik toestaan.
Zal dit mijn computer vertragen?
Terwijl de AI draait, gebruikt hij CPU/GPU-bronnen. Maar als je hem sluit, keert alles terug naar normaal. Het is net als bij het uitvoeren van elke andere applicatie.
Kan ik dit gebruiken voor werk?
Dat hangt af van het beleid van je werkgever. Aangezien alles lokaal draait en je gegevens je machine niet verlaten, is het over het algemeen veiliger dan cloud-AI. Maar controleer dit eerst bij je IT-afdeling.
Moet ik online zijn?
Alleen voor de initiële download van modellen. Daarna werkt alles volledig offline.
Mijn ervaring
Ik gebruik mijn lokale AI nu een tijdje en ik ben onder de indruk. Het is niet zo capabel als GPT-5, Claude Sonnet 4.5 of Gemini 2.5, maar voor veel taken (e-mails schrijven, ideeën brainstormen, vragen beantwoorden) is het meer dan goed genoeg.
Wat ik het meest waardeer, is het privacyaspect. Mijn gesprekken blijven op mijn machine. Er worden geen gegevens naar externe servers gestuurd. Er worden geen trainingsdatasets ergens naartoe gevoerd. Dit maakt het beter geschikt voor het werken met vertrouwelijke informatie in vergelijking met cloud-AI, hoewel je nog steeds het beveiligingsbeleid van je organisatie moet volgen.
Is het perfect? Nee. Antwoorden kunnen soms traag zijn als ik een groter model draai. En de kwaliteit is niet helemaal op het niveau van de beste cloud-AI's. Maar voor een gratis, privé, altijd beschikbare assistent? Die afweging neem ik graag.