Uw eigen AI-assistent toevoegen aan uw website zonder enterprise-kosten
Aangepaste RAG-oplossingen zoals AI-chatbots hoeven niet duur te zijn. Je kunt ze gratis draaien met behulp van Cloudflare's royale gratis abonnement.
Enterprise-platforms zoals AWS Kendra of Azure AI Search kunnen oplopen tot duizenden per maand, terwijl opties zoals Pinecone's starter-tier of zelf-gehoste oplossingen met pgvector budgetvriendelijkere alternatieven bieden. Na betrokkenheid bij verschillende RAG-projecten, heb ik gemerkt dat Cloudflare AI Search een goede optie kan zijn, afhankelijk van je behoeften. Het past niet bij elke use case, maar voor veel scenario's neemt het het meeste zware werk uit handen.
Dit bericht beschrijft hoe ik een chatbot voor deze site heb gebouwd met behulp van Cloudflare AI Search. Ik zal bespreken wat RAG is, hoe AI Search de pijplijn vereenvoudigt, implementatiedetails (streaming, opslag, rate limiting), werkelijke kosten en hoe dit schaalt naar zakelijke use cases.
Hoewel dit een persoonlijke site is (mijn digitale tuin), is dezelfde architectuur van toepassing, of je nu een persoonlijke website of bedrijfsdocumentatie indexeert.
Wat is RAG?
RAG (Retrieval-Augmented Generation) is een patroon dat LLM-antwoorden baseert op jouw feitelijke gegevens. In plaats van uitsluitend te vertrouwen op de trainingsgegevens van het model, haalt RAG relevante inhoud uit je documenten en neemt deze op in de prompt.
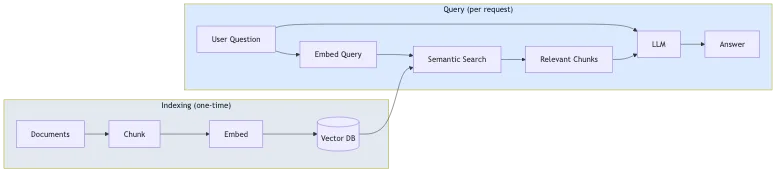
Het proces bestaat uit twee fasen:
- Indexering (eenmalig): Je documenten worden opgesplitst in 'chunks', omgezet in vector embeddings en opgeslagen in een vector database
- Query (per aanvraag): De vraag van de gebruiker wordt 'embedded', vergelijkbare chunks worden opgehaald via semantisch zoeken en de LLM genereert een antwoord met die chunks als context
Deze aanpak vermindert hallucinaties omdat het model antwoordt op basis van jouw inhoud, en niet alleen op basis van zijn algemene kennis. Het betekent ook dat je een model niet telkens opnieuw hoeft te 'fine-tunen' wanneer je inhoud verandert.
Wat Cloudflare AI Search daadwerkelijk doet
Voordat we in de implementatie duiken, is het nuttig om te begrijpen wat AI Search (voorheen AutoRAG genoemd) standaard biedt:
- Automatische indexering: Wijs het naar je website of gegevensbron, en het crawlt en indexeert je inhoud automatisch
- Vector embeddings: Het genereert en beheert de embeddings voor semantisch zoeken
- RAG-pijplijn: Het haalt relevante inhoud op en genereert antwoorden met die context
- Continue updates: Wanneer je inhoud verandert, wordt de index automatisch bijgewerkt
Dit betekent dat je de logica voor chunking, embedding, vectoropslag of retrieval niet zelf hoeft te bouwen. AI Search regelt dat allemaal.
Architectuur overzicht
Dit is wat ik daadwerkelijk heb gebouwd:
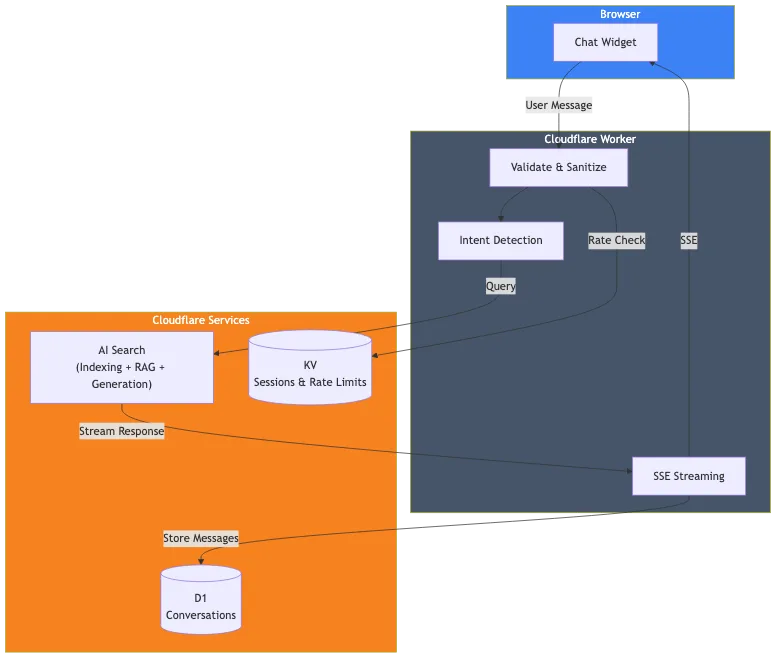
De componenten zijn:
- Cloudflare AI Search: Indexeert deze website en beheert de RAG-pijplijn
- Cloudflare Worker: Verwerkt aanvragen, validatie en streaming van antwoorden
- Cloudflare D1: Slaat conversatiegeschiedenis op voor analyse
- Cloudflare KV: Beheert sessies en rate limiting
De kernimplementatie
De daadwerkelijke AI Search-aanroep is eenvoudig. Dit is het belangrijkste deel:
// Haal de AI-binding op uit de Cloudflare-context
const ai = await getCloudflareAI();
// Roep AI Search aan
const aiSearch = ai.autorag('jouw-ai-search-instantie');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});Dat is het voor het RAG-gedeelte. AI Search neemt de zoekopdracht van de gebruiker, doorzoekt mijn geïndexeerde website-inhoud, haalt relevante stukken op en genereert een antwoord met die context.
AI Search instellen
Om AI Search te gebruiken, moet je:
- Een AI Search-instantie maken in het Cloudflare-dashboard
- Je gegevensbron koppelen (in mijn geval deze website)
- Wachten tot de initiële indexering voltooid is
- De AI-binding toevoegen aan je wrangler.toml
# wrangler.toml
[ai]
binding = "AI"Eenmaal geconfigureerd, bewaakt AI Search continu je gegevensbron en werkt de index bij wanneer de inhoud verandert.
De systeemprompt
De systeemprompt definieert hoe de AI zich moet gedragen. Hier vorm je de persoonlijkheid en grenzen van de chatbot:
function getSystemPrompt(locale: string): string {
return `Je bent een behulpzame AI-assistent op de portfolio website van David Loor.
## KRITIEKE REGELS:
1. Reageer ALTIJD in ${languageNames[locale]}
2. Beantwoord ALLEEN vragen over David Loor - je bent GEEN algemene assistent
3. Gebruik de verstrekte context over David - verzin geen informatie
## Je Gedrag:
- Wees behulpzaam en professioneel
- Houd antwoorden beknopt (maximaal 2-3 alinea's)
- Vermeld, indien van toepassing, dat ze een gesprek kunnen boeken of een e-mail kunnen sturen
- Bespreek geen prijzen - stel voor dit direct te bespreken
- Doe niet alsof je David bent - je bent zijn AI-assistent`;
}Het gedeelte met kritieke regels is belangrijk. Zonder expliciete grenzen zal de chatbot proberen algemene kennisvragen te beantwoorden, wat niet is wat ik wil voor een portfolio-assistent.
Antwoorden streamen
Niemand wil wachten tot een volledig antwoord zichtbaar is. AI Search ondersteunt streaming standaard met stream: true. Je kunt het antwoord rechtstreeks naar de client sturen met behulp van Server-Sent Events (SSE), waardoor gebruikers dat vertrouwde ChatGPT-achtige type-effect krijgen.
Gesprekken opslaan met D1
Als je gesprekken wilt analyseren of je chatbot in de loop van de tijd wilt verbeteren, kun je ze opslaan in Cloudflare D1 (hun serverloze SQLite). Voer de database-schrijfbewerkingen gewoon op de achtergrond uit, zodat ze de streamingrespons niet blokkeren.
Rate limiting met KV
Openbare API's hebben bescherming nodig. Ik gebruik Cloudflare KV voor eenvoudige rate limiting:
const RATE_LIMIT_WINDOW_MS = 60000; // 1 minuut
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 berichten per minuut
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// Nieuw venster
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Rate limited
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}Lokale ontwikkeling
Voor lokale ontwikkeling gebruik ik npx wrangler dev, wat de Worker lokaal uitvoert terwijl deze verbinding maakt met mijn productie Cloudflare-services (AI Search, D1, KV). Dit geeft me een productie-achtige omgeving zonder te hoeven implementeren:
npx wrangler devDe Worker-code draait op mijn machine, maar de bindingen maken verbinding met de echte externe services. Dit betekent dat lokale ontwikkeling je 'neuron'-quotum gebruikt, maar het is de meest nauwkeurige manier om te testen voordat je implementeert.
Wat dit mij kostte
Hier is het goede nieuws: je kunt deze hele stack draaien op het gratis abonnement van Cloudflare. Geen betaald abonnement vereist.
| Service | Limieten Gratis Abonnement |
|---|---|
| AI Search | Beschikbaar op alle abonnementen (inclusief gratis) |
| Workers AI | 10.000 neurons/dag |
| D1 | 5M reads/dag, 100K writes/dag, 5GB opslag |
| KV | 100K reads/dag, 1K writes/dag, 1GB opslag |
| Workers | 100K verzoeken/dag |
De belangrijkste limiet die je zult bereiken, zijn de Workers AI-neurons. Laten we rekenen.
Workers AI (de belangrijkste kostenpost)
Je krijgt gratis 10.000 neurons per dag (ongeveer 300.000/maand). Een typische chatinteractie met AI Search gebruikt ongeveer 500-1.000 neurons, afhankelijk van de lengte van het antwoord. Dat betekent:
- ~300-600 chatberichten per dag voordat de gratis limiet wordt overschreden
- ~9.000-18.000 berichten per maand inbegrepen
Voor de meeste persoonlijke sites en kleine bedrijven is dat meer dan genoeg om volledig gratis te draaien. Daarboven betaal je $0,011 per 1.000 neurons. Een drukke chatbot die 1.000 berichten/dag verwerkt, zou ongeveer $5-10/maand extra kosten.
Andere services (royale limieten)
De andere limieten van het gratis abonnement zijn genereus:
- Workers verzoeken: 100K/dag. Dat zijn ~100K chatberichten per dag voordat limieten worden bereikt.
- D1 reads: 5M/dag. Elke chat gebruikt een paar 'reads', dus duizenden chats per dag.
- D1 writes: 100K/dag. Elk bericht slaat 2 rijen op, dus ~50K berichten/dag.
- KV reads: 100K/dag. Rate limiting gebruikt ~2 reads per bericht.
Voor de meeste sites zijn Workers AI-neurons de enige limiet die je realistisch gezien zult benaderen. De andere services hebben dagelijkse limieten die worden gereset, wat je veel speelruimte geeft.
Wat ik niet heb gebouwd
Het is vermeldenswaard wat AI Search voor mij heeft afgehandeld:
- Document chunking: Ik heb geen chunking-logica geschreven
- Embedding generatie: AI Search genereert en beheert embeddings
- Vectoropslag: Geen noodzaak om Vectorize afzonderlijk in te stellen
- Retrieval-logica: AI Search beheert semantisch zoeken
- Indexupdates: Wijzigingen in inhoud worden automatisch opgepikt
Als ik dit vanaf nul had gebouwd met afzonderlijke embeddings, vector database en retrieval-pijplijn, zou het aanzienlijk meer werk zijn geweest. AI Search abstraheert dat allemaal.
Schaalvergroting naar zakelijke use cases
Hoewel ik dit voor mijn persoonlijke site heb gebouwd, is hetzelfde patroon van toepassing op zakelijke scenario's. AI Search ondersteunt naast websites ook andere gegevensbronnen:
Klantenservice
Wijs AI Search naar je documentatiesite, helppagina of kennisbank. De chatbot kan productvragen, probleemoplossingsvragen en beleidsvragen beantwoorden zonder een aangepast model te trainen. Voeg logica toe om indien nodig te escaleren naar menselijke medewerkers.
Interne kennisassistent
Indexeer je bedrijfswiki, Confluence of interne documentatie. Werknemers kunnen vragen stellen in natuurlijke taal in plaats van door mappen te zoeken. De systeemprompt definieert toegangsbeperkingen en antwoordstijl.
E-commerce productadviseur
Indexeer je productcataloguspagina's. Klanten kunnen vragen "welke laptop is goed voor videobewerking onder de $1000" en antwoorden krijgen die gebaseerd zijn op je werkelijke inventaris. Routeer klanten die klaar zijn om te kopen naar de kassa.
Wat verandert bij schaalvergroting
De kernarchitectuur blijft hetzelfde. Wat verandert:
- Gegevensbron: In plaats van een persoonlijke website, koppel je je bedrijfscontent
- Systeemprompt: Afgestemd op je merkstem en use case
- Bedrijfslogica: Aangepaste routering op basis van gebruikersbehoeften
- Rate limits: Aangepast op basis van verwachte verkeer
- Authenticatie: Voeg gebruikersauthenticatie toe bij het indexeren van privé-inhoud
AI Search beheert de RAG-complexiteit, ongeacht of je 50 pagina's of 50.000 indexeert.
Model flexibiliteit
AI Search is niet vergrendeld aan één enkel model. Je hebt opties:
Generatiemodellen: AI Search ondersteunt modellen van meerdere providers, waaronder Anthropic (Claude 3.5, Claude 4), Google (Gemini 2.5 Flash/Pro), OpenAI (GPT-4o, GPT-5), plus Cerebras, Grok, Groq en Workers AI. Je kunt een 'Smart Default' selecteren die Cloudflare automatisch bijwerkt, of een specifiek model kiezen. Generatiemodellen kunnen zelfs per aanvraag worden overschreven via de API.
Embedding modellen: Opties zijn onder meer OpenAI's text-embedding-3-modellen, Google's Gemini Embedding en de BGE-modellen van Workers AI. Het embedding-model wordt ingesteld tijdens de initiële configuratie en kan later niet meer worden gewijzigd (dit zou een volledige herindexering vereisen).
Breng je eigen model mee: Als de ondersteunde modellen niet aan je behoeften voldoen, kun je je eigen generatiemodel meenemen via AI Gateway of door AI Search alleen voor retrieval te gebruiken en de resultaten naar een willekeurige externe LLM te sturen.
Beperkingen
Deze aanpak heeft enkele beperkingen:
- Cloudflare-specifiek: AI Search werkt alleen binnen het ecosysteem van Cloudflare
- Beperkte retrieval-afstemming: Je kunt de chunkgrootte en overlap aanpassen, maar niet de onderliggende chunking-strategie of het retrieval-algoritme
- Beperkte gegevensbronnen: AI Search ondersteunt websites en R2-opslag (voor PDF's, documenten, enz.), maar niet willekeurige databases of API's rechtstreeks
Voor complexere use cases (aangepaste chunking, meerdere heterogene gegevensbronnen of gespecialiseerde retrieval) zou je meer van de pijplijn zelf moeten bouwen met behulp van Vectorize en Workers AI rechtstreeks.
Probeer de chatbot in de hoek van deze pagina. Deze draait precies wat ik hier heb beschreven.
Als je iets soortgelijks bouwt en de details wilt bespreken, laten we dan praten.