Perché ho scelto Server-Sent Events rispetto a WebSockets per lo streaming delle risposte AI
Quando ho creato Kindle-ChatGPT, avevo bisogno di trasmettere in streaming le risposte dell'AI al client in tempo reale. Conosci quella sensazione soddisfacente di guardare ChatGPT digitare la sua risposta parola per parola? Volevo quella stessa sensazione.
Il mio primo istinto è stato quello di ricorrere ai WebSockets. È la soluzione di riferimento per la comunicazione in tempo reale, giusto? Ma dopo alcune ricerche, ho capito che c'era una soluzione più semplice ed elegante nascosta in bella vista: Server-Sent Events (SSE).
Cosa sono i Server-Sent Events?
Server-Sent Events è uno standard che consente ai server di inviare dati ai client tramite una singola connessione HTTP. A differenza dei WebSockets, SSE è unidirezionale: il server invia dati al client, ma non viceversa.
Il protocollo è sorprendentemente semplice. Il server risponde con Content-Type: text/event-stream e invia i dati in questo formato:
data: Ciao
data: Mondo
data: {"messaggio": "Anche JSON funziona"}
Ogni messaggio è preceduto da data: ed è separato da due nuove righe. Tutto qui. Niente handshake, niente analisi dei frame, niente aggiornamenti di connessione.
Perché SSE invece di WebSockets?
Il punto è questo riguardo allo streaming delle risposte dell'AI: il client invia una domanda e il server trasmette la risposta. È fondamentalmente un flusso unidirezionale. Perché dovrei impostare una comunicazione bidirezionale quando ho bisogno di dati che viaggiano solo in una direzione?
I WebSockets funzionerebbero, ma comportano un sovraccarico:
- Aggiornamento della connessione: I WebSockets richiedono un handshake di aggiornamento HTTP
- Gestione della connessione persistente: È necessario gestire la logica di riconnessione, gli heartbeat e lo stato della connessione
- Complessità dell'infrastruttura: Alcuni proxy e CDN non gestiscono bene i WebSockets
- Più codice: Sia il client che il server necessitano di implementazioni più complesse
SSE, d'altra parte:
- Utilizza HTTP standard: Funziona tramite qualsiasi proxy, CDN o load balancer che gestisca HTTP
- Riconnessione integrata: L'API
EventSourcedel browser si riconnette automaticamente - Protocollo semplice: Solo testo su HTTP
- Supporto nativo del browser: Nessuna libreria necessaria sul client
Per il mio caso d'uso, lo streaming di testo da un modello AI, SSE è stata la scelta ovvia.
Come l'API Gemini utilizza SSE
Ecco qualcosa che inizialmente non avevo capito: l'API Gemini di Google supporta nativamente SSE per lo streaming delle risposte. Basta aggiungere ?alt=sse all'endpoint:
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
L'API restituisce un flusso di eventi, ognuno contenente un frammento della risposta:
data: {"candidates":[{"content":{"parts":[{"text":"Ciao"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" lì"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":"!"}],"role":"model"}}]}
Creazione di un proxy di streaming con TransformStream
Il mio server funge da proxy tra il client e Gemini. Ma non volevo inoltrare il formato SSE grezzo di Gemini al client. La struttura JSON annidata (candidates[0].content.parts[0].text) è inutilmente complessa per la mia semplice interfaccia di chat.
Invece, ho utilizzato un TransformStream per analizzare gli eventi SSE ed estrarre solo il testo:
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Mantiene la riga incompleta nel buffer
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Gestisce gli errori di analisi con grazia
}
}
}
},
flush(controller) {
// Elabora qualsiasi dato rimanente nel buffer
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Gestisce gli errori di analisi finali
}
}
}
});
C'è un dettaglio sottile ma importante qui: gli eventi SSE potrebbero essere suddivisi tra i frammenti di rete. Una singola riga data: potrebbe arrivare in due pezzi. Il buffer gestisce questo mantenendo le righe incomplete fino all'arrivo del frammento successivo.
L'implementazione lato client
Sul client, potrei usare l'API nativa EventSource. Ma poiché il mio flusso trasformato invia testo semplice (non formato SSE), ho usato direttamente l'API ReadableStream:
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// Aggiorna l'UI con il messaggio accumulato
setMessage(fullMessage);
}
Questa è la bellezza dello streaming: ogni frammento arriva man mano che l'AI lo genera, e possiamo aggiornare l'UI immediatamente.
Ottimizzazione per display e-ink
Qui è dove il mio caso d'uso specifico è diventato interessante. I display e-ink del Kindle hanno basse frequenze di aggiornamento. Se aggiornassi l'UI ad ogni singolo frammento, lo schermo sfarfallerebbe costantemente e farebbe fatica a tenere il passo.
La soluzione è stata l'aggiornamento limitato (throttled):
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Aggiorna ogni 500ms
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Aggiorna sempre con il contenuto finale
setMessage(fullMessage);
Questo raggruppa gli aggiornamenti dell'UI in intervalli di 500 ms pur ricevendo i dati alla massima velocità con cui arrivano. Il testo si accumula in memoria e il display si aggiorna a un ritmo che lo schermo e-ink può gestire.
Gestione degli errori e casi limite
Il codice di produzione deve gestire diversi casi limite:
1. Errori di rete a metà streaming
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Elabora il frammento
}
} catch (error) {
// Si è verificato un errore di rete
// Mostra messaggio parziale + indicatore di errore
setMessage(fullMessage + '\n\n[Connessione interrotta]');
}
2. JSON malformato dall'API
Il try-catch del TransformStream assicura che un singolo frammento errato non interrompa l'intero flusso. Registriamo l'errore e continuiamo l'elaborazione.
3. Risposte vuote
A volte l'API restituisce frammenti senza contenuto di testo. Il chaining opzionale (?.) lo gestisce con grazia.
Quando usare SSE rispetto a WebSockets
Dopo questa esperienza, ecco il mio modello mentale:
Usa SSE quando:
- I dati fluiscono principalmente dal server al client
- Hai bisogno di un'implementazione semplice con infrastruttura minima
- La riconnessione automatica è utile
- Stai trasmettendo in streaming testo, log, notifiche o eventi
Usa WebSockets quando:
- Hai bisogno di comunicazione bidirezionale
- La bassa latenza è fondamentale (giochi, modifica collaborativa)
- Stai inviando dati binari
- Devi inviare messaggi frequenti dal client al server
Per le applicazioni di chat AI, SSE è la scelta ideale. L'utente invia un messaggio (richiesta POST normale) e l'AI trasmette la risposta (SSE). Semplice, efficiente e funziona ovunque.
Considerazioni sulla distribuzione (Deployment)
Ho distribuito questo su Cloudflare Workers e SSE ha funzionato senza alcuna configurazione speciale. L'ambiente di esecuzione Workers supporta nativamente lo streaming delle risposte:
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Alcune cose da notare:
- Nessuna cache: Le risposte in streaming non dovrebbero mai essere memorizzate nella cache
- Keep-alive: Aiuta a mantenere la connessione per flussi più lunghi
- Content-Type: Ho usato
text/plainpoiché sto inviando testo grezzo, non formato SSE
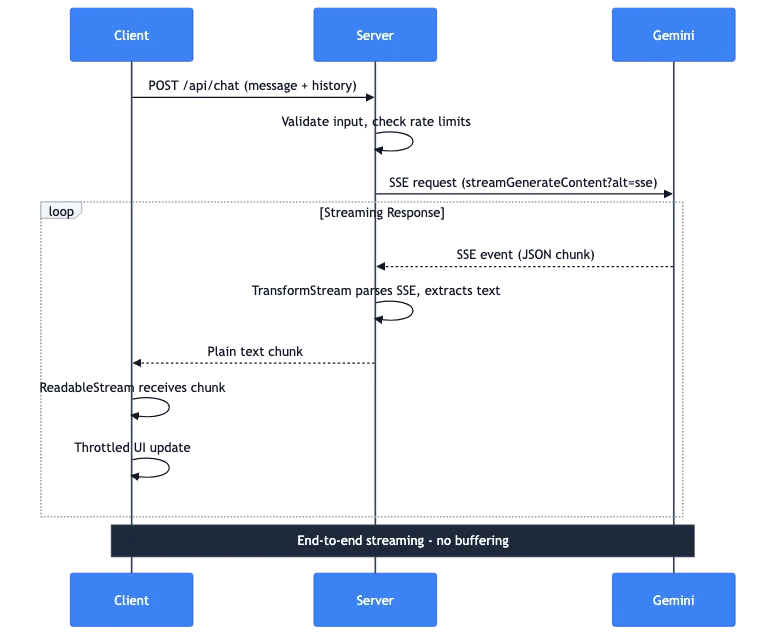
Il flusso di dati completo
Vi illustro cosa succede quando un utente invia un messaggio:
- Client: Richiesta POST con messaggio e cronologia della conversazione
- Server: Convalida l'input, controlla i limiti di frequenza (rate limits)
- Server: Effettua una richiesta SSE all'API Gemini
- Gemini: Trasmette eventi SSE con frammenti JSON
- Server: TransformStream analizza SSE, estrae il testo
- Server: Inoltra frammenti di testo semplice al client
- Client: ReadableStream riceve i frammenti
- Client: Gli aggiornamenti dell'UI limitati visualizzano il testo
L'intera pipeline viene trasmessa end-to-end. Nessun buffering della risposta completa sul server. Il primo token da Gemini raggiunge lo schermo dell'utente in millisecondi.