Come eseguire LLM (IA) open source sul tuo computer?
Ho configurato il mio assistente AI che funziona completamente sul mio computer. Nessuna connessione Internet necessaria. Nessun dato inviato al cloud.
Se eri curioso di eseguire la tua AI ma pensavi che richiedesse una laurea in informatica, ho buone notizie: è più facile di quanto pensi.
Perché vorresti un LLM (AI) locale?
Prima di addentrarci nel come, parliamo del perché. Eseguire LLM (AI) in locale presenta alcuni vantaggi reali:
- Privacy: Le tue conversazioni non lasciano mai il tuo computer. Nessuna azienda memorizza, analizza o addestra sui tuoi dati.
- Nessun Internet richiesto: Una volta configurato, puoi usare la tua AI ovunque: in aereo, in un bar con Wi-Fi intermittente o in mezzo al nulla.
- È gratuito: Dopo la configurazione iniziale, non ci sono costi di abbonamento o costi API.
- È tuo: Controlli tutto. Nessun limite di frequenza, nessun filtro sui contenuti, nessun cambiamento dei termini di servizio.
Cosa ti servirà
Ecco cosa mi è servito per iniziare (e servirà anche a te):
- Un computer ragionevolmente moderno (Windows, Mac o Linux)
- Circa 30 minuti del tuo tempo
- Circa 4-8 GB di spazio libero su disco (a seconda del modello che scegli)
Questo è tutto. Non è necessaria una costosa GPU, anche se se ne hai una, le cose andranno più veloci.
Cos'è llama.cpp?
Prima di passare all'installazione, lascia che ti spieghi cosa stiamo effettivamente installando.
llama.cpp è un software che ti permette di eseguire Large Language Models (AI) sul tuo computer. Pensalo come il motore che fa funzionare tutto. Questi modelli sono solo file di dati, come file video o musicali. llama.cpp è il lettore che sa come usarli.
È open source, gratuito e mantenuto attivamente. Funziona su Mac, Windows e Linux, ed è progettato per essere veloce anche su computer normali senza schede grafiche particolari.
Installazione
Il modo più semplice per installare llama.cpp è tramite un gestore di pacchetti.
Se usi un Mac o Linux
Apri il terminale e digita:
brew install llama.cppQuesta è l'installazione. Seriamente.
Se usi Windows
Apri PowerShell ed esegui:
winget install llama.cppEseguire il tuo primo modello AI
Qui le cose si fanno interessanti. Non devi scaricare manualmente i file dei modelli o capire dove metterli. Lo strumento fa tutto lui per te.
Ecco cosa digitare per iniziare a chattare con un'AI:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Questo scarica ed esegue il modello Llama 3.2 3B da Hugging Face.
Lascia che ti spieghi cosa fa in parole povere:
llama-cliavvia l'interfaccia di chat-hfgli dice di scaricare da Hugging Face (un repository di LLM)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0è il modello specifico da usare
L'identificatore del modello ha tre parti separate da barre e due punti:
bartowskiè il nome utente di chi ha caricato il modello su Hugging FaceLlama-3.2-3B-Instruct-GGUFè il nome del repository che contiene il modelloQ8_0è la specifica versione di quantizzazione (qualità rispetto alla dimensione)
Quando esegui questo comando, il modello viene scaricato automaticamente (potrebbe richiedere alcuni minuti la prima volta) e poi puoi iniziare a chattare. Digita le tue domande e l'AI risponde lì nel tuo terminale.
Come trovare e usare modelli diversi
Il modello che ho menzionato sopra (Llama 3.2) è un buon punto di partenza. È relativamente piccolo e veloce, anche su hardware modesto. Ma ci sono centinaia di altri modelli che puoi provare.
Trovare modelli su Hugging Face
GGUF è il formato di file utilizzato da llama.cpp. I modelli su Hugging Face sono disponibili in diversi formati, ma llama.cpp necessita specificamente dei file GGUF.
Vai su huggingface.co/models e cerca GGUF. Cerca repository che terminano con -GGUF nel nome.
Quando trovi un modello che vuoi provare, cliccaci sopra e cerca il nome del repository. Ad esempio, se vedi bartowski/Qwen2.5-7B-Instruct-GGUF, puoi eseguire:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Suggerimenti per la scelta dei modelli:
- Numeri più piccoli = più veloce, ma meno capace: Un modello 3B è più veloce di un modello 7B, che è più veloce di un modello 13B. Il numero si riferisce a quanti miliardi di parametri ha il modello.
- Cerca "Instruct" o "Chat" nel nome: Questi modelli sono specificamente addestrati per le conversazioni.
- La parte :Q8_0: Questo è il livello di quantizzazione. Q8_0 è un buon equilibrio tra qualità e dimensione. Q4_0 è più piccolo/veloce ma di qualità leggermente inferiore.
Fare un passo avanti: Eseguire un server AI
Una volta che ti senti a tuo agio con la chat di base, puoi passare al livello successivo eseguendo la tua AI come server. Questo ti permette di chattare con essa dal tuo browser web e di usarla con altre app.
Esegui questo comando:
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Vedrai un output simile a:
main: server is listening on http://127.0.0.1:8080 - starting the main loopOra apri http://127.0.0.1:8080 (o http://localhost:8080) nel tuo browser web. Vedrai un'interfaccia di chat dove puoi parlare con la tua AI direttamente dal browser. Nessun software aggiuntivo necessario.
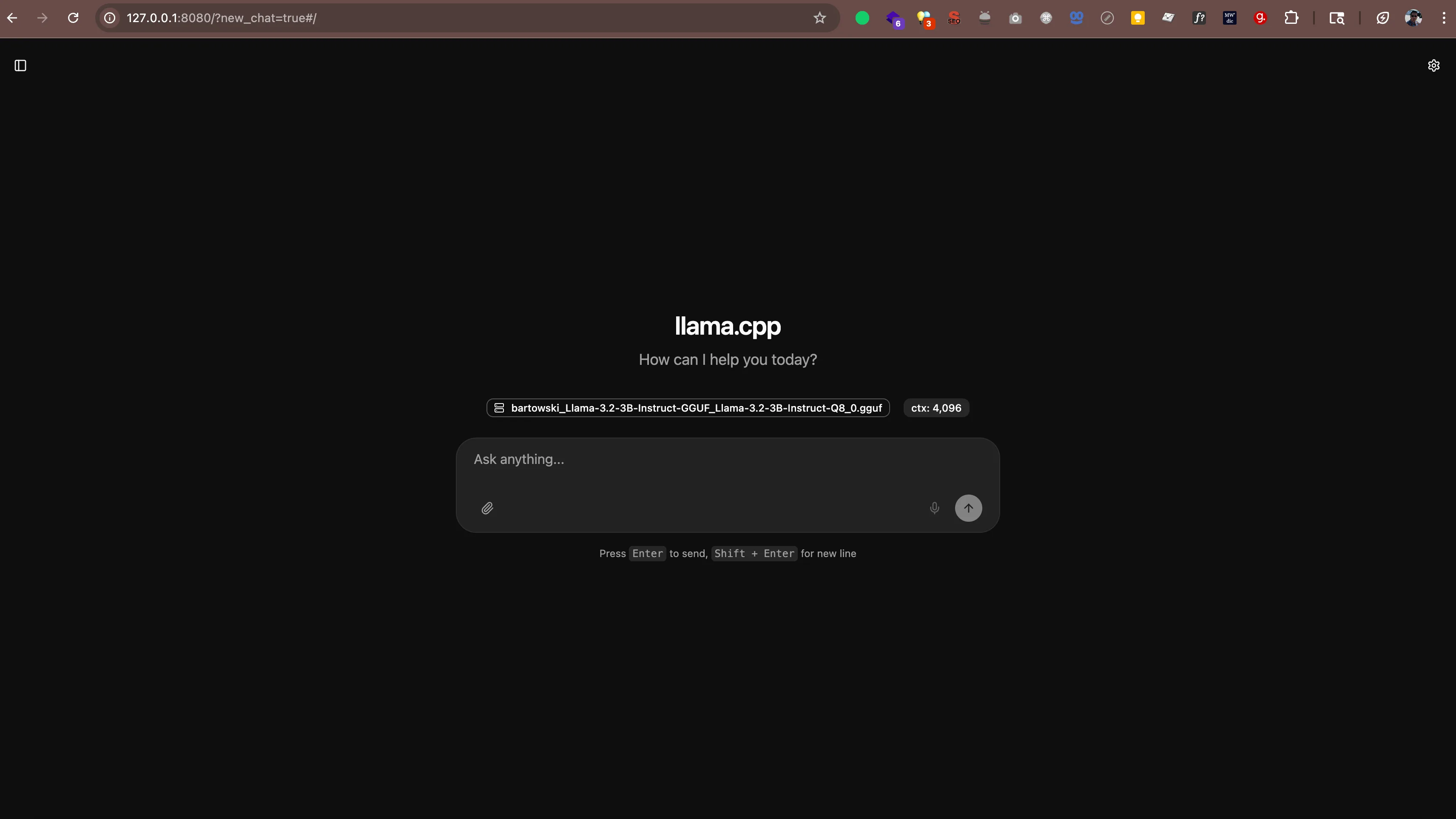
Il server funziona anche con qualsiasi app che supporti il formato API di OpenAI. Ciò significa che puoi utilizzare strumenti come:
- Continue.dev (assistente di codifica AI in VS Code)
- Open WebUI (un'interfaccia simile a ChatGPT)
- Qualsiasi altra app che supporti endpoint API personalizzati
Dove vengono memorizzati i modelli
Quando esegui questi comandi, i modelli vengono scaricati automaticamente in una cartella cache. Per impostazione predefinita, si trova nella tua directory home sotto .cache/llama.cpp.
Se vuoi cambiare la posizione in cui vengono memorizzati i modelli, puoi impostare una variabile d'ambiente:
# Su Mac/Linux
export LLAMA_CACHE=/percorso/alla/tua/cache
# Su Windows (PowerShell)
$env:LLAMA_CACHE="C:\percorso\alla\tua\cache"E le prestazioni?
Ecco cosa ho imparato sulle prestazioni:
- Sui Mac più recenti (M1/M2/M3/M4): I modelli funzionano sorprendentemente veloci. I chip della serie M hanno un'accelerazione AI integrata.
- Su Windows/Linux con una GPU decente: Anche veloce. Se hai una GPU NVIDIA, llama.cpp la userà automaticamente.
- Su computer più vecchi o laptop senza GPU: Funziona comunque! Limitatevi ai modelli più piccoli (3B o 7B) e aspettatevi risposte più lente.
Per riferimento, sul mio M4 Pro con 48 GB di RAM, un modello 3B genera testo a circa 60-65 token al secondo. È abbastanza veloce da sembrare una conversazione reale.
llama.cpp contro Ollama contro vLLM
Potresti aver sentito parlare di altri strumenti come Ollama o vLLM. Ecco come si confrontano:
Ollama
Ollama è costruito su llama.cpp. Aggiunge un'interfaccia più semplice e una gestione automatica dei modelli, ma questa comodità comporta un sovraccarico di prestazioni. Nei miei test su un Mac M4 Pro con 48 GB di RAM, llama.cpp è stato di un ordine di grandezza più veloce di Ollama che eseguiva gli stessi modelli.
Se desideri le massime prestazioni e non ti dispiace usare la riga di comando, attieniti a llama.cpp. Se preferisci una gestione dei modelli più semplice e puoi accettare velocità leggermente inferiori, Ollama funziona bene.
vLLM
vLLM non supporta macOS. È solo per Linux ed è progettato per implementazioni server ad alto throughput con più GPU. Se sei su un Mac, non è un'opzione.
In sintesi
Per gli utenti Mac, specialmente su Apple Silicon (M1/M2/M3/M4), llama.cpp è la scelta migliore. È l'opzione più veloce e ha l'accelerazione Metal nativa. Ollama va bene se desideri una gestione più semplice. vLLM non è disponibile su Mac.
Domande che potresti avere
È legale?
Sì. I modelli su Hugging Face sono open source e gratuiti da usare. Molti sono pubblicati da Meta (Facebook), Mistral AI e altre organizzazioni che consentono esplicitamente l'uso personale e commerciale.
Rallenterà il mio computer?
Mentre l'AI è in esecuzione, utilizza le risorse della CPU/GPU. Ma quando la chiudi, tutto torna alla normalità. È come eseguire qualsiasi altra applicazione.
Posso usarlo per lavoro?
Dipende dalle politiche del tuo lavoro. Poiché tutto viene eseguito in locale e i tuoi dati non lasciano la tua macchina, è generalmente più sicuro dell'AI cloud. Ma verifica prima con il tuo reparto IT.
Devo essere online?
Solo per il download iniziale dei modelli. Dopodiché, tutto funziona completamente offline.
La mia esperienza
Ho usato la mia AI locale e sono impressionato. Non è potente come GPT-5, Claude Sonnet 4.5 o Gemini 2.5, ma per molte attività (scrivere email, fare brainstorming di idee, rispondere a domande) è più che sufficiente.
Ciò che apprezzo di più è l'aspetto della privacy. Le mie conversazioni rimangono sulla mia macchina. Nessun dato inviato a server esterni. Nessun set di dati di addestramento inviato chissà dove. Questo lo rende più adatto a lavorare con informazioni riservate rispetto all'AI cloud, anche se dovresti comunque seguire le politiche di sicurezza della tua organizzazione.
È perfetto? No. Le risposte a volte possono essere lente se sto eseguendo un modello più grande. E la qualità non è ancora al livello delle migliori AI cloud. Ma per un assistente gratuito, privato e sempre disponibile? Accetto questo compromesso.