Aggiungere il tuo assistente AI al tuo sito web senza costi enterprise
Le soluzioni RAG personalizzate come le chatbot AI non devono essere costose. Puoi eseguirle gratuitamente utilizzando il generoso piano gratuito di Cloudflare.
Piattaforme enterprise come AWS Kendra o Azure AI Search possono arrivare a migliaia di euro al mese, mentre opzioni come il piano starter di Pinecone o soluzioni self-hosted con pgvector offrono alternative più economiche. Dopo aver partecipato a diversi progetti RAG, ho scoperto che Cloudflare AI Search può essere una buona opzione a seconda delle tue esigenze. Non si adatterà a ogni caso d'uso, ma per molti scenari gestisce la maggior parte del lavoro pesante.
Questo post illustra come ho creato una chatbot per questo sito utilizzando Cloudflare AI Search. Tratterò cos'è RAG, come AI Search semplifica la pipeline, i dettagli di implementazione (streaming, archiviazione, limitazione della frequenza) i costi reali e come questo si adatta ai casi d'uso aziendali.
Sebbene questo sia un sito personale (il mio giardino digitale), la stessa architettura si applica sia che tu stia indicizzando un sito web personale o la documentazione aziendale.
Cos'è RAG?
RAG (Retrieval-Augmented Generation) è un modello che fonda le risposte degli LLM sui tuoi dati effettivi. Invece di fare affidamento esclusivamente sui dati di addestramento del modello, RAG recupera contenuti pertinenti dai tuoi documenti e li include nel prompt.
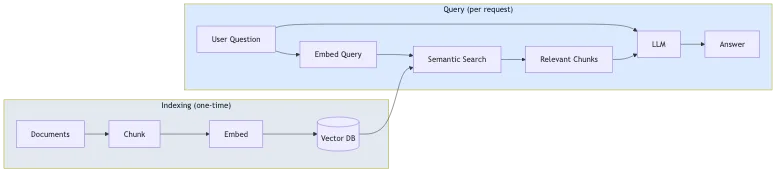
Il processo ha due fasi:
- Indicizzazione (una tantum): I tuoi documenti vengono suddivisi in blocchi (chunk), convertiti in embedding vettoriali e archiviati in un database vettoriale
- Interrogazione (per richiesta): La domanda dell'utente viene convertita in embedding, blocchi simili vengono recuperati tramite ricerca semantica e l'LLM genera una risposta utilizzando tali blocchi come contesto
Questo approccio riduce le allucinazioni perché il modello risponde basandosi sui tuoi contenuti, non solo sulla sua conoscenza generale. Significa anche che non è necessario eseguire il fine-tuning di un modello ogni volta che il contenuto cambia.
Cosa fa effettivamente Cloudflare AI Search
Prima di addentrarci nell'implementazione, vale la pena capire cosa offre AI Search (precedentemente chiamato AutoRAG) “out of the box”:
- Indicizzazione automatica: Indicalo al tuo sito web o alla fonte di dati ed esso esegue la scansione e indicizza automaticamente i tuoi contenuti
- Embedding vettoriali: Genera e gestisce gli embedding per la ricerca semantica
- Pipeline RAG: Recupera contenuti pertinenti e genera risposte utilizzando tale contesto
- Aggiornamenti continui: Quando il tuo contenuto cambia, l'indice si aggiorna automaticamente
Ciò significa che non è necessario creare la logica di suddivisione in blocchi, embedding, archiviazione vettoriale o recupero. AI Search gestisce tutto questo.
Panoramica dell'architettura
Ecco cosa ho effettivamente costruito:
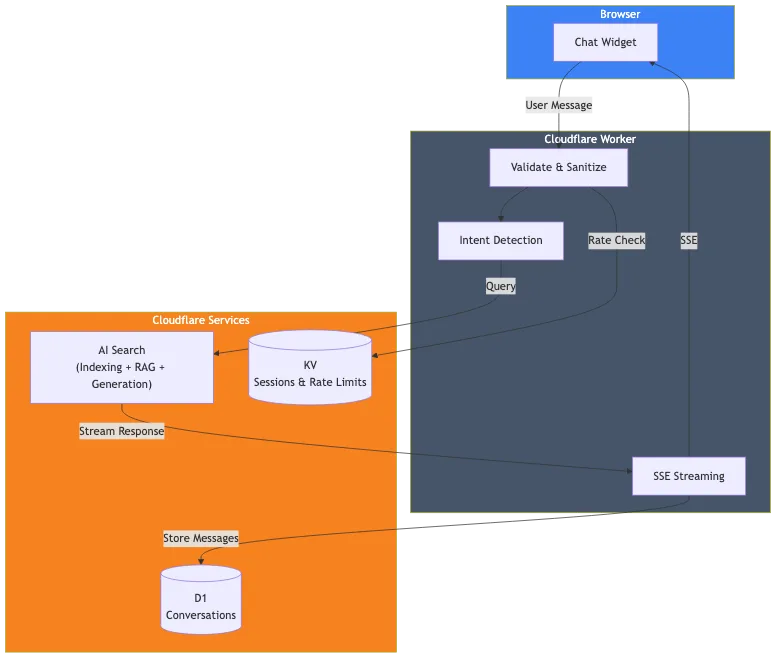
I componenti sono:
- Cloudflare AI Search: Indicizza questo sito web e gestisce la pipeline RAG
- Cloudflare Worker: Gestisce le richieste, la convalida e lo streaming delle risposte
- Cloudflare D1: Archivia la cronologia delle conversazioni per l'analisi
- Cloudflare KV: Gestisce le sessioni e la limitazione della frequenza (rate limiting)
L'implementazione principale
La chiamata effettiva ad AI Search è semplice. Ecco la parte fondamentale:
// Ottieni il binding AI dal contesto Cloudflare
const ai = await getCloudflareAI();
// Chiama AI Search
const aiSearch = ai.autorag('your-ai-search-instance');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});Questo è tutto per la parte RAG. AI Search prende la query dell'utente, cerca i contenuti indicizzati del mio sito web, recupera i blocchi pertinenti e genera una risposta utilizzando tale contesto.
Configurazione di AI Search
Per utilizzare AI Search, devi:
- Creare un'istanza di AI Search nel pannello di controllo di Cloudflare
- Collegare la tua fonte di dati (nel mio caso, questo sito web)
- Attendere il completamento dell'indicizzazione iniziale
- Aggiungere il binding AI al tuo wrangler.toml
# wrangler.toml
[ai]
binding = "AI"Una volta configurato, AI Search monitora continuamente la tua fonte di dati e aggiorna l'indice quando il contenuto cambia.
Il prompt di sistema
Il prompt di sistema definisce come l'AI dovrebbe comportarsi. È qui che si modella la personalità e i limiti della chatbot:
function getSystemPrompt(locale: string): string {
return `Sei un assistente AI utile sul sito portfolio di David Loor.
## REGOLE CRITICHE:
1. Rispondi SEMPRE in ${languageNames[locale]}
2. Rispondi SOLO a domande su David Loor - NON sei un assistente generico
3. Usa il contesto fornito su David - non inventare informazioni
## Il tuo comportamento:
- Sii utile e professionale
- Mantieni le risposte concise (massimo 2-3 paragrafi)
- Quando appropriato, menziona che possono prenotare una chiamata o inviare un'e-mail
- Non discutere di prezzi - suggerisci di parlarne direttamente
- Non fingere di essere David - sei il suo assistente AI`;
}La sezione delle regole critiche è importante. Senza confini espliciti, la chatbot cercherà di rispondere a domande di conoscenza generale, che non è ciò che voglio per un assistente di portfolio.
Streaming delle risposte
Nessuno vuole aspettare una risposta completa prima di vedere qualcosa. AI Search supporta lo streaming “out of the box” con stream: true. Puoi inoltrare la risposta direttamente al client utilizzando Server-Sent Events (SSE), dando agli utenti quel familiare effetto di digitazione in stile ChatGPT.
Archiviazione delle conversazioni con D1
Se desideri analizzare le conversazioni o migliorare la tua chatbot nel tempo, puoi archiviarle in Cloudflare D1 (il loro SQLite serverless). Esegui semplicemente le scritture del database in background in modo che non blocchino la risposta in streaming.
Limitazione della frequenza con KV
Le API pubbliche necessitano di protezione. Utilizzo Cloudflare KV per una semplice limitazione della frequenza:
const RATE_LIMIT_WINDOW_MS = 60000; // 1 minuto
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 messaggi al minuto
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// Nuova finestra
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Frequenza limitata
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}Sviluppo locale
Per lo sviluppo locale, utilizzo npx wrangler dev che esegue il Worker localmente mentre si connette ai miei servizi Cloudflare di produzione (AI Search, D1, KV). Questo mi offre un ambiente simile alla produzione senza dover effettuare il deploy:
npx wrangler devIl codice del Worker viene eseguito sulla mia macchina, ma i binding si collegano ai servizi remoti reali. Ciò significa che lo sviluppo locale utilizza la tua quota di neuroni, ma è il modo più accurato per testare prima del deploy.
Quanto mi è costato
Ecco la buona notizia: puoi eseguire l'intero stack sul piano gratuito di Cloudflare. Nessun piano a pagamento richiesto.
| Servizio | Limiti del Piano Gratuito |
|---|---|
| AI Search | Disponibile su tutti i piani (incluso quello gratuito) |
| Workers AI | 10.000 neuroni/giorno |
| D1 | 5M letture/giorno, 100K scritture/giorno, 5GB di spazio di archiviazione |
| KV | 100K letture/giorno, 1K scritture/giorno, 1GB di spazio di archiviazione |
| Workers | 100K richieste/giorno |
Il limite principale che incontrerai sono i neuroni di Workers AI. Facciamo i conti.
Workers AI (il costo principale)
Ottieni 10.000 neuroni gratuiti al giorno (circa 300.000/mese). Una tipica interazione di chat con AI Search utilizza circa 500-1.000 neuroni a seconda della lunghezza della risposta. Ciò significa:
- Circa 300-600 messaggi di chat al giorno prima di superare il piano gratuito
- Circa 9.000-18.000 messaggi al mese inclusi
Per la maggior parte dei siti personali e delle piccole imprese, è più che sufficiente per funzionare interamente gratuitamente. Oltre tale soglia, si pagano $0,011 per 1.000 neuroni. Una chatbot trafficata che gestisce 1.000 messaggi/giorno costerebbe circa $5-10/mese in più.
Altri servizi (limiti generosi)
Gli altri limiti del piano gratuito sono generosi:
- Richieste Workers: 100K/giorno. Sono circa 100.000 messaggi di chat al giorno prima di raggiungere i limiti.
- Letture D1: 5M/giorno. Ogni chat utilizza alcune letture, quindi migliaia di chat al giorno.
- Scritture D1: 100K/giorno. Ogni messaggio archivia 2 righe, quindi circa 50.000 messaggi/giorno.
- Letture KV: 100K/giorno. La limitazione della frequenza utilizza circa 2 letture per messaggio.
Per la maggior parte dei siti, i neuroni di Workers AI sono l'unico limite che probabilmente raggiungerai. Gli altri servizi hanno limiti giornalieri che si resettano, dandoti ampio margine.
Cosa non ho costruito
Vale la pena notare cosa ha gestito AI Search per me:
- Suddivisione dei documenti (Chunking): Non ho scritto alcuna logica di suddivisione in blocchi
- Generazione di embedding: AI Search genera e gestisce gli embedding
- Archiviazione vettoriale: Nessuna necessità di configurare Vectorize separatamente
- Logica di recupero: AI Search gestisce la ricerca semantica
- Aggiornamenti dell'indice: Le modifiche al contenuto vengono rilevate automaticamente
Se avessi costruito questo da zero con embedding separati, database vettoriale e pipeline di recupero, sarebbe stato un lavoro significativamente maggiore. AI Search astrae tutto questo.
Scalare ai casi d'uso aziendali
Sebbene l'abbia costruito per il mio sito personale, lo stesso modello si applica agli scenari aziendali. AI Search supporta diverse fonti di dati oltre ai siti web:
Supporto clienti
Indica AI Search al tuo sito di documentazione, centro assistenza o knowledge base. La chatbot può rispondere a domande sui prodotti, richieste di risoluzione dei problemi e domande sulle policy senza addestrare un modello personalizzato. Aggiungi la logica per inoltrare agli agenti umani quando necessario.
Assistente di conoscenza interno
Indica il wiki aziendale, Confluence o la documentazione interna. I dipendenti possono porre domande in linguaggio naturale invece di cercare tra le cartelle. Il prompt di sistema definisce i confini di accesso e lo stile di risposta.
Consulente di prodotti e-commerce
Indica le pagine del tuo catalogo prodotti. I clienti possono chiedere "quale laptop è buono per il video editing sotto i $1000" e ottenere risposte basate sul tuo inventario effettivo. Inoltra i clienti pronti all'acquisto al checkout.
Cosa cambia su larga scala
L'architettura di base rimane la stessa. Ciò che cambia:
- Fonte dati: Invece di un sito web personale, colleghi i contenuti aziendali
- Prompt di sistema: Personalizzato in base al tono del tuo marchio e al caso d'uso
- Logica aziendale: Instradamento personalizzato in base alle esigenze dell'utente
- Limiti di frequenza: Regolati in base al traffico previsto
- Autenticazione: Aggiungi l'autenticazione utente se indicizzi contenuti privati
AI Search gestisce la complessità di RAG indipendentemente dal fatto che tu stia indicizzando 50 pagine o 50.000.
Flessibilità del modello
AI Search non è bloccato su un singolo modello. Hai delle opzioni:
Modelli di generazione: AI Search supporta modelli di diversi provider tra cui Anthropic (Claude 3.5, Claude 4), Google (Gemini 2.5 Flash/Pro), OpenAI (GPT-4o, GPT-5), oltre a Cerebras, Grok, Groq e Workers AI. Puoi selezionare un Smart Default che Cloudflare aggiorna automaticamente, oppure scegliere un modello specifico. I modelli di generazione possono persino essere sovrascritti per richiesta tramite l'API.
Modelli di embedding: Le opzioni includono i modelli text-embedding-3 di OpenAI, Gemini Embedding di Google e i modelli BGE di Workers AI. Il modello di embedding viene impostato durante la configurazione iniziale e non può essere modificato successivamente (richiederebbe il re-indexing di tutto).
Porta il tuo modello: Se i modelli supportati non soddisfano le tue esigenze, puoi portare il tuo modello di generazione tramite AI Gateway o utilizzando AI Search solo per il recupero e inviando i risultati a qualsiasi LLM esterno.
Limitazioni
Questo approccio presenta alcuni vincoli:
- Specifico di Cloudflare: AI Search funziona solo all'interno dell'ecosistema di Cloudflare
- Ottimizzazione limitata del recupero: Puoi regolare la dimensione e la sovrapposizione dei blocchi (chunk size and overlap), ma non la strategia di suddivisione in blocchi sottostante o l'algoritmo di recupero
- Fonti di dati limitate: AI Search supporta siti web e archiviazione R2 (per PDF, documenti, ecc.), ma non database o API arbitrari direttamente
Per casi d'uso più complessi (suddivisione in blocchi personalizzata, più fonti di dati eterogenee o recupero specializzato), dovresti costruire più della pipeline da solo utilizzando direttamente Vectorize e Workers AI.
Prova la chatbot nell'angolo di questa pagina. Sta eseguendo esattamente ciò che ho descritto qui.
Se stai costruendo qualcosa di simile e vuoi discutere i dettagli, parliamone.