Pourquoi j'ai choisi les Server-Sent Events plutôt que les WebSockets pour le streaming des réponses d'IA
Lorsque j'ai créé Kindle-ChatGPT, j'avais besoin de diffuser les réponses de l'IA au client en temps réel. Vous connaissez cette expérience satisfaisante de regarder ChatGPT taper sa réponse mot par mot ? Je voulais cette même sensation.
Mon premier réflexe a été de me tourner vers les WebSockets. C'est la solution de référence pour la communication en temps réel, n'est-ce pas ? Mais après quelques recherches, j'ai réalisé qu'il existait une solution plus simple et plus élégante, cachée à la vue de tous : les Server-Sent Events (SSE).
Que sont les Server-Sent Events ?
Server-Sent Events est une norme qui permet aux serveurs de pousser des données vers les clients via une seule connexion HTTP. Contrairement aux WebSockets, les SSE sont unidirectionnels : le serveur envoie des données au client, mais pas l'inverse.
Le protocole est étonnamment simple. Le serveur répond avec Content-Type: text/event-stream et envoie les données dans ce format :
data: Bonjour
data: Monde
data: {"message": "Le JSON fonctionne aussi"}
Chaque message est préfixé par data: et séparé par deux sauts de ligne. C'est tout. Pas de poignée de main (handshake), pas d'analyse de trames, pas de mise à niveau de connexion.
Pourquoi SSE plutôt que WebSockets ?
Voici le point concernant la diffusion en continu des réponses d'IA : le client envoie une question, et le serveur diffuse la réponse. C'est fondamentalement un flux unidirectionnel. Pourquoi établir une communication bidirectionnelle alors que je n'ai besoin de données que dans un seul sens ?
Les WebSockets fonctionneraient, mais ils entraînent une surcharge :
- Mise à niveau de connexion : Les WebSockets nécessitent une poignée de main de mise à niveau HTTP
- Gestion de la connexion persistante : Vous devez gérer la logique de reconnexion, les battements de cœur (heartbeats) et l'état de la connexion
- Complexité de l'infrastructure : Certains proxys et CDN ne gèrent pas bien les WebSockets
- Plus de code : Le client et le serveur nécessitent des implémentations plus complexes
SSE, en revanche :
- Utilise le HTTP standard : Fonctionne via n'importe quel proxy, CDN ou répartiteur de charge qui gère le HTTP
- Reconnexion intégrée : L'API
EventSourcedu navigateur se reconnecte automatiquement - Protocole simple : Juste du texte sur HTTP
- Prise en charge native par le navigateur : Aucune bibliothèque nécessaire côté client
Pour mon cas d'utilisation, la diffusion de texte à partir d'un modèle d'IA, SSE était le choix évident.
Comment l'API Gemini utilise SSE
Voici quelque chose que je n'avais pas réalisé au début : l'API Gemini de Google prend en charge nativement SSE pour la diffusion des réponses. Il suffit d'ajouter ?alt=sse à l'endpoint :
const apiUrl = `https://generativelanguage.googleapis.com/v1beta/models/${GEMINI_MODEL}:streamGenerateContent?alt=sse&key=${API_KEY}`;
const response = await fetch(apiUrl, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
contents: [{ role: 'user', parts: [{ text: userMessage }] }],
generationConfig: {
temperature: 0.7,
maxOutputTokens: 2048,
},
}),
});
L'API renvoie un flux d'événements, contenant chacun un morceau de la réponse :
data: {"candidates":[{"content":{"parts":[{"text":"Bonjour"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" là"}],"role":"model"}}]}
data: {"candidates":[{"content":{"parts":[{"text":" !"}],"role":"model"}}]}
Création d'un proxy de diffusion avec TransformStream
Mon serveur agit comme un proxy entre le client et Gemini. Mais je ne voulais pas transmettre le format SSE brut de Gemini au client. La structure JSON imbriquée (candidates[0].content.parts[0].text) est inutilement complexe pour mon interface de chat simple.
J'ai donc utilisé un TransformStream pour analyser les événements SSE et n'extraire que le texte :
const transformStream = new TransformStream({
transform(chunk, controller) {
const text = new TextDecoder().decode(chunk);
buffer += text;
const lines = buffer.split('\n');
buffer = lines.pop() || ''; // Conserver la ligne incomplète dans le buffer
for (const line of lines) {
if (line.startsWith('data: ')) {
try {
const json = JSON.parse(line.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Gérer les erreurs d'analyse avec élégance
}
}
}
},
flush(controller) {
// Traiter les données restantes dans le buffer
if (buffer.startsWith('data: ')) {
try {
const json = JSON.parse(buffer.slice(6));
const content = json.candidates?.[0]?.content?.parts?.[0]?.text;
if (content) {
controller.enqueue(new TextEncoder().encode(content));
}
} catch (e) {
// Gérer les erreurs d'analyse finales
}
}
}
});
Il y a un détail subtil mais important ici : les événements SSE peuvent être répartis sur plusieurs morceaux réseau. Une seule ligne data: peut arriver en deux morceaux. Le buffer gère cela en conservant les lignes incomplètes jusqu'à l'arrivée du morceau suivant.
L'implémentation côté client
Côté client, j'aurais pu utiliser l'API native EventSource. Mais comme mon flux transformé envoie du texte brut (et non au format SSE), j'ai utilisé directement l'API ReadableStream :
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ message, history }),
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let fullMessage = '';
while (true) {
const { done, value } = await reader.read();
if (done) break;
const chunk = decoder.decode(value);
fullMessage += chunk;
// Mettre à jour l'interface utilisateur avec le message accumulé
setMessage(fullMessage);
}
C'est la beauté du streaming : chaque morceau arrive au fur et à mesure que l'IA le génère, et nous pouvons mettre à jour l'interface utilisateur immédiatement.
Optimisation pour les écrans e-ink
C'est là que mon cas d'utilisation spécifique est devenu intéressant. Les écrans e-ink des Kindle ont des taux de rafraîchissement lents. Si je mettais à jour l'interface utilisateur à chaque morceau, l'écran scintillerait constamment et aurait du mal à suivre.
La solution était des mises à jour limitées (throttled) :
let lastUpdateTime = 0;
const UPDATE_INTERVAL = 500; // Mettre à jour toutes les 500 ms
while (true) {
const { done, value } = await reader.read();
if (done) break;
fullMessage += decoder.decode(value);
const now = Date.now();
if (now - lastUpdateTime >= UPDATE_INTERVAL) {
lastUpdateTime = now;
setMessage(fullMessage);
}
}
// Toujours mettre à jour avec le contenu final
setMessage(fullMessage);
Ceci regroupe les mises à jour de l'interface utilisateur par intervalles de 500 ms tout en continuant de recevoir les données aussi vite qu'elles arrivent. Le texte s'accumule en mémoire, et l'affichage se met à jour à un rythme que l'écran e-ink peut gérer.
Gestion des erreurs et cas limites
Le code de production doit gérer plusieurs cas limites :
1. Erreurs réseau en milieu de flux
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// Traiter le morceau
}
} catch (error) {
// Erreur réseau survenue
// Afficher le message partiel + indicateur d'erreur
setMessage(fullMessage + '\n\n[Connexion interrompue]');
}
2. JSON mal formé provenant de l'API
Le try-catch du TransformStream garantit qu'un seul mauvais morceau ne casse pas l'intégralité du flux. Nous enregistrons l'erreur et continuons le traitement.
3. Réponses vides
Parfois, l'API renvoie des morceaux sans contenu textuel. Le chaînage optionnel (?.) gère cela avec élégance.
Quand utiliser SSE vs WebSockets
Après cette expérience, voici mon modèle mental :
Utiliser SSE lorsque :
- Les données circulent principalement du serveur vers le client
- Vous avez besoin d'une implémentation simple avec une infrastructure minimale
- La reconnexion automatique est précieuse
- Vous diffusez du texte, des journaux, des notifications ou des événements
Utiliser WebSockets lorsque :
- Vous avez besoin d'une communication bidirectionnelle
- La faible latence est critique (jeux, édition collaborative)
- Vous envoyez des données binaires
- Vous devez envoyer des messages fréquents du client au serveur
Pour les applications de chat IA, SSE trouve le juste milieu. L'utilisateur envoie un message (requête POST standard), et l'IA diffuse la réponse (SSE). Simple, efficace et cela fonctionne partout.
Considérations de déploiement
J'ai déployé ceci sur Cloudflare Workers, et SSE a fonctionné sans aucune configuration spéciale. L'environnement d'exécution Workers prend en charge nativement la diffusion des réponses :
return new Response(stream, {
headers: {
'Content-Type': 'text/plain; charset=utf-8',
'Cache-Control': 'no-cache, no-store, must-revalidate',
'Connection': 'keep-alive',
},
});
Quelques points à noter :
- Pas de mise en cache : Les réponses diffusées ne doivent jamais être mises en cache
- Keep-alive : Aide à maintenir la connexion pour les flux plus longs
- Content-Type : J'ai utilisé
text/plaincar j'envoie du texte brut, et non au format SSE
Le flux de données complet
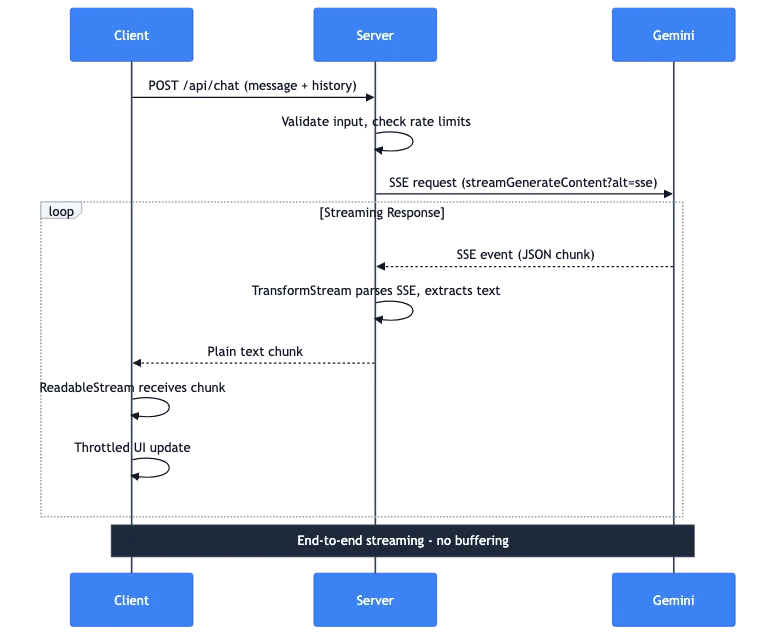
Laissez-moi vous expliquer ce qui se passe lorsqu'un utilisateur envoie un message :
- Client : Requête POST avec le message et l'historique de la conversation
- Serveur : Valide les entrées, vérifie les limites de débit
- Serveur : Effectue une requête SSE vers l'API Gemini
- Gemini : Diffuse des événements SSE avec des morceaux JSON
- Serveur : TransformStream analyse le SSE, extrait le texte
- Serveur : Transmet les morceaux de texte brut au client
- Client : ReadableStream reçoit les morceaux
- Client : Les mises à jour d'interface utilisateur limitées affichent le texte
L'ensemble du pipeline est diffusé de bout en bout. Aucune mise en mémoire tampon de la réponse complète sur le serveur. Le premier jeton de Gemini atteint l'écran de l'utilisateur en quelques millisecondes.