Comment exécuter des LLM open source (IA) sur votre ordinateur ?
J'ai configuré mon propre assistant IA qui fonctionne entièrement sur mon ordinateur. Aucune connexion Internet n'est nécessaire. Aucune donnée n'est envoyée vers le cloud.
Si vous avez été curieux d'exécuter votre propre IA mais pensiez que cela nécessitait un diplôme en informatique, j'ai une bonne nouvelle : c'est plus facile que vous ne le pensez.
Pourquoi voudriez-vous un LLM (IA) local ?
Avant de plonger dans le comment, parlons du pourquoi. L'exécution locale des LLM (IA) présente de réels avantages :
- Confidentialité : Vos conversations ne quittent jamais votre ordinateur. Aucune entreprise ne stocke, n'analyse ou n'entraîne ses modèles sur vos données.
- Aucune connexion Internet requise : Une fois configuré, vous pouvez utiliser votre IA n'importe où : dans un avion, dans un café avec un Wi-Fi intermittent, ou au milieu de nulle part.
- C'est gratuit : Après la configuration initiale, il n'y a pas de frais d'abonnement ni de coûts d'API.
- C'est à vous : Vous contrôlez tout. Pas de limites de débit, pas de filtres de contenu, pas de changements dans les conditions d'utilisation.
Ce dont vous aurez besoin
Voici ce dont j'avais besoin pour commencer (et vous aurez besoin de la même chose) :
- Un ordinateur raisonnablement moderne (Windows, Mac ou Linux)
- Environ 30 minutes de votre temps
- Environ 4 à 8 Go d'espace disque libre (selon le modèle que vous choisissez)
C'est tout. Pas besoin de carte graphique coûteuse, bien que si vous en avez une, les choses s'exécuteront plus rapidement.
Qu'est-ce que llama.cpp ?
Avant de plonger dans l'installation, laissez-moi vous expliquer ce que nous installons réellement.
llama.cpp est un logiciel qui vous permet d'exécuter des grands modèles de langage (IA) sur votre ordinateur. Considérez-le comme le moteur qui fait fonctionner l'ensemble. Ces modèles ne sont que des fichiers de données, comme des fichiers vidéo ou musicaux. llama.cpp est le lecteur qui sait comment les utiliser.
Il est open source, gratuit et activement maintenu. Il fonctionne sur Mac, Windows et Linux, et il est conçu pour être rapide même sur des ordinateurs ordinaires sans cartes graphiques sophistiquées.
Installation
La manière la plus simple d'installer llama.cpp est via un gestionnaire de paquets.
Si vous êtes sur Mac ou Linux
Ouvrez votre terminal et tapez :
brew install llama.cppC'est l'installation. Sérieusement.
Si vous êtes sur Windows
Ouvrez PowerShell et exécutez :
winget install llama.cppExécuter votre premier modèle d'IA
C'est là que ça devient passionnant. Vous n'avez pas besoin de télécharger manuellement les fichiers de modèle ou de déterminer où les placer. L'outil fait tout pour vous.
Voici ce que vous tapez pour commencer à discuter avec une IA :
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Ceci télécharge et exécute le modèle Llama 3.2 3B depuis Hugging Face.
Laissez-moi décomposer ce que cela fait en langage clair :
llama-clidémarre l'interface de discussion-hflui indique de télécharger depuis Hugging Face (un dépôt de LLM)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0est le modèle spécifique à utiliser
L'identifiant du modèle comporte trois parties séparées par des barres obliques et un deux-points :
bartowskiest le nom d'utilisateur de celui qui a téléchargé le modèle sur Hugging FaceLlama-3.2-3B-Instruct-GGUFest le nom du dépôt contenant le modèleQ8_0est la version de quantification spécifique (qualité par rapport à la taille)
Lorsque vous exécutez cette commande, le modèle se télécharge automatiquement (cela peut prendre quelques minutes la première fois), puis vous pouvez commencer à discuter. Tapez vos questions et l'IA répond directement dans votre terminal.
Comment trouver et utiliser différents modèles
Le modèle que j'ai mentionné ci-dessus (Llama 3.2) est un bon point de départ. Il est relativement petit et rapide, même sur du matériel modeste. Mais il existe des centaines d'autres modèles que vous pouvez essayer.
Trouver des modèles sur Hugging Face
GGUF est le format de fichier que llama.cpp utilise. Les modèles sur Hugging Face existent dans différents formats, mais llama.cpp a spécifiquement besoin de fichiers GGUF.
Allez sur huggingface.co/models et recherchez GGUF. Recherchez les dépôts dont le nom se termine par -GGUF.
Lorsque vous trouvez un modèle que vous souhaitez essayer, cliquez dessus et recherchez le nom du dépôt. Par exemple, si vous voyez bartowski/Qwen2.5-7B-Instruct-GGUF, vous pouvez exécuter :
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Conseils pour choisir des modèles :
- Nombres plus petits = plus rapide, mais moins performant : Un modèle 3B est plus rapide qu'un modèle 7B, qui est plus rapide qu'un modèle 13B. Le nombre fait référence au nombre de milliards de paramètres que possède le modèle.
- Recherchez « Instruct » ou « Chat » dans le nom : Ces modèles sont spécifiquement entraînés pour les conversations.
- La partie :Q8_0 : C'est le niveau de quantification. Q8_0 est un bon équilibre entre qualité et taille. Q4_0 est plus petit/plus rapide mais légèrement de qualité inférieure.
Passer à l'étape suivante : Exécuter un serveur d'IA
Une fois que vous êtes à l'aise avec la discussion de base, vous pouvez passer au niveau supérieur en exécutant votre IA comme un serveur. Cela vous permet de discuter avec elle depuis votre navigateur Web et de l'utiliser avec d'autres applications.
Exécutez cette commande :
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0Vous verrez une sortie comme :
main: server is listening on http://127.0.0.1:8080 - starting the main loopMaintenant, ouvrez http://127.0.0.1:8080 (ou http://localhost:8080) dans votre navigateur Web. Vous verrez une interface de discussion où vous pourrez parler à votre IA directement depuis le navigateur. Aucun logiciel supplémentaire n'est nécessaire.
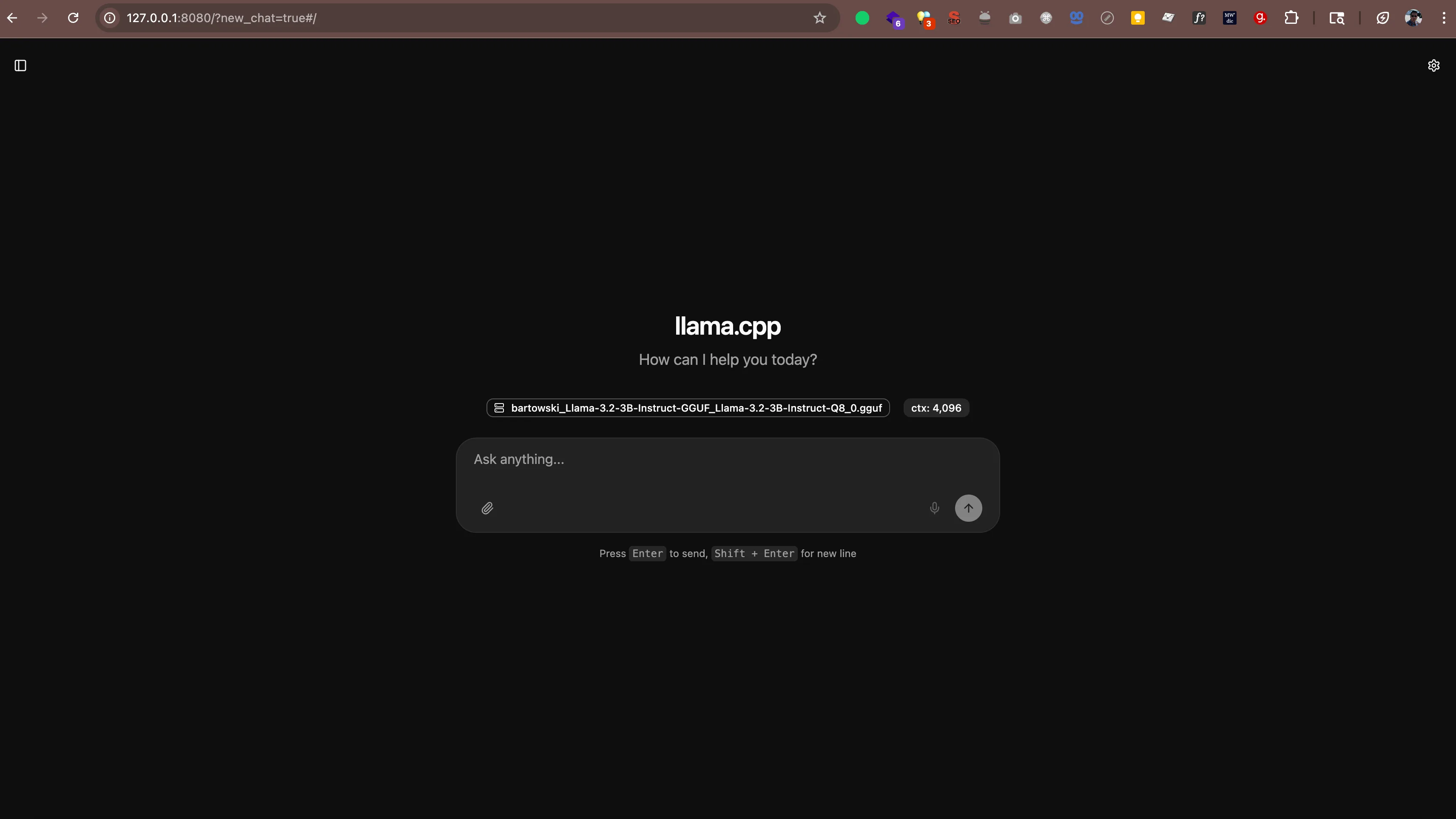
Le serveur fonctionne également avec toute application qui prend en charge le format d'API d'OpenAI. Cela signifie que vous pouvez utiliser des outils tels que :
- Continue.dev (assistant de codage IA dans VS Code)
- Open WebUI (une interface de type ChatGPT)
- Toute autre application qui prend en charge les points de terminaison d'API personnalisés
Où les modèles sont stockés
Lorsque vous exécutez ces commandes, les modèles sont téléchargés automatiquement dans un dossier de cache. Par défaut, il se trouve dans votre répertoire personnel sous .cache/llama.cpp.
Si vous souhaitez modifier l'emplacement de stockage des modèles, vous pouvez définir une variable d'environnement :
# Sur Mac/Linux
export LLAMA_CACHE=/chemin/vers/votre/cache
# Sur Windows (PowerShell)
$env:LLAMA_CACHE="C:\chemin\vers\votre\cache"Qu'en est-il des performances ?
Voici ce que j'ai appris sur les performances :
- Sur les Macs plus récents (M1/M2/M3/M4) : Les modèles s'exécutent étonnamment vite. Les puces de la série M disposent d'une accélération IA intégrée.
- Sur Windows/Linux avec un GPU décent : Également rapide. Si vous avez un GPU NVIDIA, llama.cpp l'utilisera automatiquement.
- Sur les ordinateurs plus anciens ou les ordinateurs portables sans GPU : Cela fonctionne toujours ! Tenez-vous-en aux modèles plus petits (3B ou 7B) et attendez-vous à des réponses plus lentes.
À titre de référence, sur mon M4 Pro avec 48 Go de RAM, un modèle 3B génère du texte à environ 60 à 65 jetons par seconde. C'est assez rapide pour ressembler à une vraie conversation.
llama.cpp contre Ollama contre vLLM
Vous avez peut-être entendu parler d'autres outils comme Ollama ou vLLM. Voici comment ils se comparent :
Ollama
Ollama est construit sur llama.cpp. Il ajoute une interface plus simple et une gestion automatique des modèles, mais cette commodité s'accompagne d'une surcharge de performance. Dans mes tests sur un Mac M4 Pro avec 48 Go de RAM, llama.cpp était un ordre de grandeur plus rapide qu'Ollama exécutant les mêmes modèles.
Si vous souhaitez des performances maximales et que cela ne vous dérange pas d'utiliser la ligne de commande, restez avec llama.cpp. Si vous préférez une gestion des modèles plus facile et que vous pouvez accepter des vitesses légèrement plus lentes, Ollama fonctionne bien.
vLLM
vLLM ne prend pas en charge macOS. Il est réservé à Linux et conçu pour les déploiements de serveurs à haut débit avec plusieurs GPU. Si vous êtes sur un Mac, ce n'est pas une option.
En résumé
Pour les utilisateurs de Mac, en particulier sur Apple Silicon (M1/M2/M3/M4), llama.cpp est le meilleur choix. C'est l'option la plus rapide et elle dispose d'une accélération Metal native. Ollama convient si vous souhaitez une gestion plus simple. vLLM n'est pas disponible sur Mac.
Questions que vous pourriez vous poser
Est-ce légal ?
Oui. Les modèles sur Hugging Face sont open source et gratuits à utiliser. Beaucoup sont publiés par Meta (Facebook), Mistral AI et d'autres organisations qui autorisent explicitement l'utilisation personnelle et commerciale.
Est-ce que cela va ralentir mon ordinateur ?
Tant que l'IA fonctionne, elle utilise les ressources du CPU/GPU. Mais lorsque vous la fermez, tout redevient normal. C'est comme exécuter n'importe quelle autre application.
Puis-je l'utiliser pour le travail ?
Cela dépend des politiques de votre travail. Étant donné que tout s'exécute localement et que vos données ne quittent pas votre machine, c'est généralement plus sûr que l'IA cloud. Mais vérifiez d'abord auprès de votre service informatique.
Ai-je besoin d'être en ligne ?
Seulement pour le téléchargement initial des modèles. Après cela, tout fonctionne complètement hors ligne.
Mon expérience
J'utilise mon IA locale et je suis impressionné. Elle n'est pas tout à fait aussi performante que GPT-5, Claude Sonnet 4.5 ou Gemini 2.5, mais pour de nombreuses tâches (écrire des e-mails, brainstormer des idées, répondre à des questions), elle est plus que suffisante.
Ce que j'apprécie le plus, c'est l'aspect confidentialité. Mes conversations restent sur ma machine. Aucune donnée n'est envoyée à des serveurs externes. Aucun ensemble de données d'entraînement n'est transmis ailleurs. Cela le rend mieux adapté au travail avec des informations confidentielles par rapport à l'IA cloud, bien que vous devriez toujours suivre les politiques de sécurité de votre organisation.
Est-ce parfait ? Non. Les réponses peuvent parfois être lentes si j'exécute un modèle plus grand. Et la qualité n'est pas tout à fait au niveau des meilleures IA cloud. Mais pour un assistant gratuit, privé et toujours disponible ? J'accepte ce compromis.