Ajouter votre propre assistant IA à votre site web sans coûts d'entreprise
Les solutions RAG personnalisées comme les chatbots IA n'ont pas besoin d'être coûteuses. Vous pouvez les exécuter gratuitement grâce au niveau gratuit généreux de Cloudflare.
Les plateformes d'entreprise comme AWS Kendra ou Azure AI Search peuvent coûter des milliers par mois, tandis que des options comme le niveau de démarrage de Pinecone ou les solutions auto-hébergées avec pgvector offrent des alternatives plus abordables. Après avoir participé à plusieurs projets RAG, j'ai constaté que Cloudflare AI Search peut être une bonne option en fonction de vos besoins. Elle ne conviendra pas à tous les cas d'utilisation, mais pour de nombreux scénarios, elle gère la majeure partie du travail lourd.
Cet article explique comment j'ai créé un chatbot pour ce site en utilisant Cloudflare AI Search. Je couvrirai ce qu'est le RAG, comment l'IA Search simplifie le pipeline, les détails d'implémentation (streaming, stockage, limitation du débit), les coûts réels et comment cela s'adapte aux cas d'utilisation professionnels.
Bien qu'il s'agisse d'un site personnel (mon jardin numérique), la même architecture s'applique que vous indexiez un site web personnel ou de la documentation d'entreprise.
Qu'est-ce que le RAG ?
RAG (Retrieval-Augmented Generation) est un modèle qui ancre les réponses des LLM dans vos données réelles. Au lieu de se fier uniquement aux données d'entraînement du modèle, le RAG récupère le contenu pertinent de vos documents et l'inclut dans l'invite (prompt).
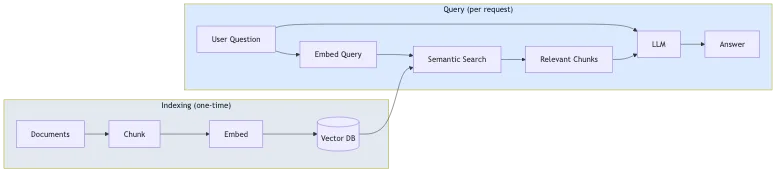
Le processus comporte deux phases :
- Indexation (une seule fois) : Vos documents sont divisés en morceaux (chunks), convertis en intégrations vectorielles (vector embeddings) et stockés dans une base de données vectorielle.
- Requête (par demande) : La question de l'utilisateur est intégrée, des morceaux similaires sont récupérés via la recherche sémantique, et le LLM génère une réponse en utilisant ces morceaux comme contexte.
Cette approche réduit les hallucinations car le modèle répond en se basant sur votre contenu, et non seulement sur ses connaissances générales. Cela signifie également que vous n'avez pas besoin d'affiner (fine-tune) un modèle chaque fois que votre contenu change.
Ce que fait réellement Cloudflare AI Search
Avant de plonger dans l'implémentation, il est utile de comprendre ce que AI Search (anciennement appelé AutoRAG) fournit nativement :
- Indexation automatique : Pointez-le vers votre site web ou votre source de données, et il explore et indexe votre contenu automatiquement.
- Intégrations vectorielles : Il génère et gère les intégrations pour la recherche sémantique.
- Pipeline RAG : Il récupère le contenu pertinent et génère des réponses en utilisant ce contexte.
- Mises à jour continues : Lorsque votre contenu change, l'index se met à jour automatiquement.
Cela signifie que vous n'avez pas besoin de construire vous-même la logique de découpage (chunking), d'intégration (embedding), de stockage vectoriel ou de récupération. AI Search gère tout cela.
Aperçu de l'architecture
Voici ce que j'ai réellement construit :
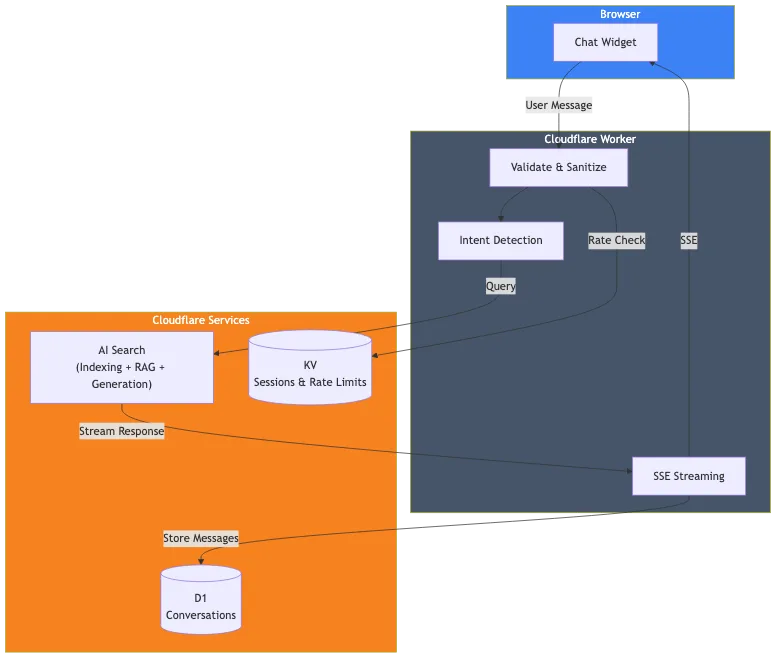
Les composants sont :
- Cloudflare AI Search : Indexe ce site web et gère le pipeline RAG.
- Cloudflare Worker : Gère les requêtes, la validation et le streaming des réponses.
- Cloudflare D1 : Stocke l'historique des conversations pour l'analyse.
- Cloudflare KV : Gère les sessions et la limitation du débit.
L'implémentation principale
L'appel AI Search réel est simple. Voici la partie clé :
// Obtenir la liaison AI du contexte Cloudflare
const ai = await getCloudflareAI();
// Appeler AI Search
const aiSearch = ai.autorag('votre-instance-ai-search');
const response = await aiSearch.aiSearch({
query: message,
system_prompt: systemPrompt,
max_num_results: 5,
stream: true
});C'est tout pour la partie RAG. AI Search prend la requête de l'utilisateur, recherche le contenu de mon site web indexé, récupère les morceaux pertinents et génère une réponse en utilisant ce contexte.
Configuration d'AI Search
Pour utiliser AI Search, vous devez :
- Créer une instance AI Search dans le tableau de bord Cloudflare.
- Connecter votre source de données (dans mon cas, ce site web).
- Attendre que l'indexation initiale soit terminée.
- Ajouter la liaison AI à votre wrangler.toml.
# wrangler.toml
[ai]
binding = "AI"Une fois configuré, AI Search surveille continuellement votre source de données et met à jour l'index lorsque le contenu change.
L'invite système (System Prompt)
L'invite système définit la manière dont l'IA doit se comporter. C'est là que vous façonnez la personnalité et les limites du chatbot :
function getSystemPrompt(locale: string): string {
return `Vous êtes un assistant IA utile sur le site portfolio de David Loor.
## RÈGLES CRITIQUES :
1. RÉPONDEZ TOUJOURS en ${languageNames[locale]}
2. NE RÉPONDEZ QU'AUX QUESTIONS concernant David Loor - vous n'êtes PAS un assistant généraliste
3. Utilisez le contexte fourni sur David - n'inventez pas d'informations
## Votre comportement :
- Soyez utile et professionnel
- Gardez les réponses concises (2-3 paragraphes maximum)
- Lorsque cela est approprié, mentionnez qu'ils peuvent réserver un appel ou envoyer un e-mail
- Ne discutez pas des prix - suggérez de discuter directement
- N'essayez pas d'être David - vous êtes son assistant IA`;
}La section des règles critiques est importante. Sans limites explicites, le chatbot essaiera de répondre à des questions de connaissances générales, ce qui n'est pas ce que je souhaite pour un assistant de portfolio.
Streaming des réponses
Personne n'a envie d'attendre une réponse complète avant de voir quoi que ce soit. AI Search prend en charge le streaming nativement avec stream: true. Vous pouvez acheminer la réponse directement vers le client en utilisant les Server-Sent Events (SSE), offrant aux utilisateurs cet effet de frappe familier à la ChatGPT.
Stockage des conversations avec D1
Si vous souhaitez analyser les conversations ou améliorer votre chatbot au fil du temps, vous pouvez les stocker dans Cloudflare D1 (leur SQLite sans serveur). Exécutez simplement les écritures de la base de données en arrière-plan afin qu'elles ne bloquent pas la réponse en streaming.
Limitation du débit avec KV
Les API publiques nécessitent une protection. J'utilise Cloudflare KV pour une limitation de débit simple :
const RATE_LIMIT_WINDOW_MS = 60000; // 1 minute
const RATE_LIMIT_MAX_REQUESTS = 15; // 15 messages par minute
async function checkRateLimit(kv: KVNamespace, sessionId: string): Promise<boolean> {
const key = `ratelimit_${sessionId}`;
const data = await kv.get<{ count: number; windowStart: number }>(key, 'json');
const now = Date.now();
if (!data || now - data.windowStart >= RATE_LIMIT_WINDOW_MS) {
// Nouvelle fenêtre
await kv.put(key, JSON.stringify({ count: 1, windowStart: now }), { expirationTtl: 120 });
return true;
}
if (data.count >= RATE_LIMIT_MAX_REQUESTS) {
return false; // Débit limité
}
await kv.put(key, JSON.stringify({ count: data.count + 1, windowStart: data.windowStart }), { expirationTtl: 120 });
return true;
}Développement local
Pour le développement local, j'utilise npx wrangler dev qui exécute le Worker localement tout en se connectant à mes services Cloudflare de production (AI Search, D1, KV). Cela me donne un environnement similaire à la production sans avoir à déployer :
npx wrangler devLe code du Worker s'exécute sur ma machine, mais les liaisons se connectent aux services distants réels. Cela signifie que le développement local utilise votre quota de neurones, mais c'est la manière la plus précise de tester avant le déploiement.
Ce que cela m'a coûté
Voici la bonne nouvelle : vous pouvez exécuter toute cette pile sur le niveau gratuit de Cloudflare. Aucun plan payant n'est requis.
| Service | Limites du niveau gratuit |
|---|---|
| AI Search | Disponible sur tous les plans (y compris gratuit) |
| Workers AI | 10 000 neurones/jour |
| D1 | 5M lectures/jour, 100K écritures/jour, 5 Go de stockage |
| KV | 100K lectures/jour, 1K écritures/jour, 1 Go de stockage |
| Workers | 100K requêtes/jour |
La principale limite que vous atteindrez est celle des neurones Workers AI. Faisons le calcul.
Workers AI (le coût principal)
Vous obtenez 10 000 neurones gratuits par jour (environ 300 000/mois). Une interaction de chat typique avec AI Search utilise environ 500 à 1 000 neurones en fonction de la longueur de la réponse. Cela signifie :
- ~300 à 600 messages de chat par jour avant de dépasser le niveau gratuit
- ~9 000 à 18 000 messages par mois inclus
Pour la plupart des sites personnels et des petites entreprises, c'est plus que suffisant pour fonctionner entièrement gratuitement. Au-delà, vous payez 0,011 $ pour 1 000 neurones. Un chatbot actif gérant 1 000 messages/jour coûterait environ 5 à 10 $/mois supplémentaires.
Autres services (limites généreuses)
Les autres limites du niveau gratuit sont généreuses :
- Requêtes Workers : 100K/jour. Cela représente ~100K messages de chat quotidiens avant d'atteindre les limites.
- Lectures D1 : 5M/jour. Chaque chat utilise quelques lectures, soit des milliers de chats par jour.
- Écritures D1 : 100K/jour. Chaque message stocke 2 lignes, soit ~50K messages/jour.
- Lectures KV : 100K/jour. La limitation du débit utilise ~2 lectures par message.
Pour la plupart des sites, les neurones Workers AI sont la seule limite que vous approcherez réellement. Les autres services ont des limites quotidiennes qui se réinitialisent, vous laissant beaucoup de marge de manœuvre.
Ce que je n'ai pas construit
Il est important de noter ce qu'AI Search a géré pour moi :
- Découpage des documents (Chunking) : Je n'ai écrit aucune logique de découpage.
- Génération d'intégrations (Embeddings) : AI Search génère et gère les intégrations.
- Stockage vectoriel : Pas besoin de configurer Vectorize séparément.
- Logique de récupération : AI Search gère la recherche sémantique.
- Mises à jour de l'index : Les changements de contenu sont capturés automatiquement.
Si j'avais construit cela à partir de zéro avec des intégrations, une base de données vectorielle et un pipeline de récupération séparés, cela aurait représenté beaucoup plus de travail. AI Search abstrait tout cela.
Mise à l'échelle pour les cas d'utilisation professionnels
Bien que j'aie construit ceci pour mon site personnel, le même modèle s'applique aux scénarios professionnels. AI Search prend en charge différentes sources de données au-delà des sites web :
Support client
Pointez AI Search vers votre site de documentation, votre centre d'aide ou votre base de connaissances. Le chatbot peut répondre aux questions sur les produits, les problèmes de dépannage et les politiques sans former de modèle personnalisé. Ajoutez une logique pour faire remonter les problèmes aux agents humains si nécessaire.
Assistant de connaissances interne
Indexez votre wiki d'entreprise, Confluence ou votre documentation interne. Les employés peuvent poser des questions en langage naturel au lieu de chercher dans des dossiers. L'invite système définit les limites d'accès et le style de réponse.
Conseiller en produits e-commerce
Indexez vos pages de catalogue de produits. Les clients peuvent demander « quel ordinateur portable est bon pour le montage vidéo à moins de 1000 $ » et obtenir des réponses basées sur votre inventaire réel. Dirigez les clients prêts à acheter vers le paiement.
Ce qui change à l'échelle
L'architecture de base reste la même. Ce qui change :
- Source de données : Au lieu d'un site web personnel, vous connectez votre contenu professionnel.
- Invite système : Adaptée à votre voix de marque et à votre cas d'utilisation.
- Logique métier : Routage personnalisé basé sur les besoins de l'utilisateur.
- Limites de débit : Ajustées en fonction du trafic attendu.
- Authentification : Ajoutez une authentification utilisateur si vous indexez du contenu privé.
AI Search gère la complexité du RAG, que vous indexiez 50 pages ou 50 000.
Flexibilité des modèles
AI Search n'est pas lié à un seul modèle. Vous avez des options :
Modèles de génération : AI Search prend en charge les modèles de plusieurs fournisseurs, notamment Anthropic (Claude 3.5, Claude 4), Google (Gemini 2.5 Flash/Pro), OpenAI (GPT-4o, GPT-5), ainsi que Cerebras, Grok, Groq et Workers AI. Vous pouvez sélectionner une valeur par défaut intelligente que Cloudflare met à jour automatiquement, ou choisir un modèle spécifique. Les modèles de génération peuvent même être remplacés par requête via l'API.
Modèles d'intégration (Embedding) : Les options incluent les modèles text-embedding-3 d'OpenAI, Gemini Embedding de Google et les modèles BGE de Workers AI. Le modèle d'intégration est défini lors de la configuration initiale et ne peut pas être modifié ultérieurement (cela nécessiterait de réindexer l'ensemble des données).
Apportez votre propre modèle : Si les modèles pris en charge ne correspondent pas à vos besoins, vous pouvez apporter votre propre modèle de génération via AI Gateway ou en utilisant AI Search uniquement pour la récupération et en envoyant les résultats à n'importe quel LLM externe.
Limitations
Cette approche présente quelques contraintes :
- Spécifique à Cloudflare : AI Search ne fonctionne qu'au sein de l'écosystème de Cloudflare.
- Réglage limité de la récupération : Vous pouvez ajuster la taille et le chevauchement des morceaux (chunk size and overlap), mais pas la stratégie de découpage sous-jacente ni l'algorithme de récupération.
- Sources de données limitées : AI Search prend en charge les sites web et le stockage R2 (pour les PDF, documents, etc.), mais pas les bases de données ou les API arbitraires directement.
Pour des cas d'utilisation plus complexes (découpage personnalisé, sources de données hétérogènes multiples ou récupération spécialisée), vous devriez construire davantage le pipeline vous-même en utilisant Vectorize et Workers AI directement.
Essayez le chatbot dans le coin de cette page. Il exécute exactement ce que j'ai décrit ici.
Si vous construisez quelque chose de similaire et souhaitez discuter des détails, discutons-en.