How to run open source LLMs (AI) on your computer?
I set up my own AI assistant that runs completely on my computer. No internet connection needed. No data sent to the cloud.
If you've been curious about running your own AI but thought it required a degree in computer science, I have good news: it's easier than you think.
Why would you want a local LLM (AI)?
Before we dive into the how, let's talk about the why. Running LLMs (AI) locally has some real advantages:
- Privacy: Your conversations never leave your computer. No company is storing, analyzing, or training on your data.
- No internet required: Once set up, you can use your AI anywhere: on a plane, in a coffee shop with spotty WiFi, or in the middle of nowhere.
- It's free: After the initial setup, there are no subscription fees or API costs.
- It's yours: You control everything. No rate limits, no content filters, no terms of service changes.
What you'll need
Here's what I needed to get started (and you'll need the same):
- A reasonably modern computer (Windows, Mac, or Linux)
- About 30 minutes of your time
- Around 4-8 GB of free disk space (depending on which model you choose)
That's it. No expensive GPU required, though if you have one, things will run faster.
What is llama.cpp?
Before we dive into installation, let me explain what we're actually installing.
llama.cpp is software that lets you run Large Language Models (AI) on your computer. Think of it as the engine that makes everything work. These models are just data files, like videos or music files. llama.cpp is the player that knows how to use them.
It's open source, free, and actively maintained. It works on Mac, Windows, and Linux, and it's designed to be fast even on regular computers without fancy graphics cards.
Installation
The easiest way to install llama.cpp is through a package manager.
If you're on a Mac or Linux
Open your terminal and type:
brew install llama.cppThat's the installation. Seriously.
If you're on Windows
Open PowerShell and run:
winget install llama.cppRunning your first AI model
This is where it gets exciting. You don't need to download model files manually or figure out where to put them. The tool does it all for you.
Here's what you type to start chatting with an AI:
llama-cli -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0This downloads and runs the Llama 3.2 3B model from Hugging Face.
Let me break down what this does in plain English:
llama-clistarts the chat interface-hftells it to download from Hugging Face (a repository of LLMs)bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0is the specific model to use
The model identifier has three parts separated by slashes and a colon:
bartowskiis the username of who uploaded the model on Hugging FaceLlama-3.2-3B-Instruct-GGUFis the repository name containing the modelQ8_0is the specific quantization version (quality vs. size)
When you run this command, the model downloads automatically (this might take a few minutes the first time), and then you can start chatting. Type your questions, and the AI responds right there in your terminal.
How to find and use different models
The model I mentioned above (Llama 3.2) is a good starting point. It's relatively small and fast, even on modest hardware. But there are hundreds of other models you can try.
Finding models on Hugging Face
GGUF is the file format that llama.cpp uses. Models on Hugging Face come in different formats, but llama.cpp specifically needs GGUF files.
Go to huggingface.co/models and search for GGUF. Look for repositories that end with -GGUF in the name.
When you find a model you want to try, click on it and look for the repository name. For example, if you see bartowski/Qwen2.5-7B-Instruct-GGUF, you can run:
llama-cli -hf bartowski/Qwen2.5-7B-Instruct-GGUF:Q8_0Tips for choosing models:
- Smaller numbers = faster, but less capable: A 3B model is faster than a 7B model, which is faster than a 13B model. The number refers to how many billions of parameters the model has.
- Look for "Instruct" or "Chat" in the name: These models are specifically trained for conversations.
- The :Q8_0 part: This is the quantization level. Q8_0 is a good balance of quality and size. Q4_0 is smaller/faster but slightly lower quality.
Taking it a step further: Running an AI server
Once you're comfortable with the basic chat, you can level up by running your AI as a server. This lets you chat with it from your web browser and use it with other apps.
Run this command:
llama-server -hf bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0You'll see output like:
main: server is listening on http://127.0.0.1:8080 - starting the main loopNow open http://127.0.0.1:8080 (or http://localhost:8080) in your web browser. You'll see a chat interface where you can talk to your AI directly from the browser. No additional software needed.
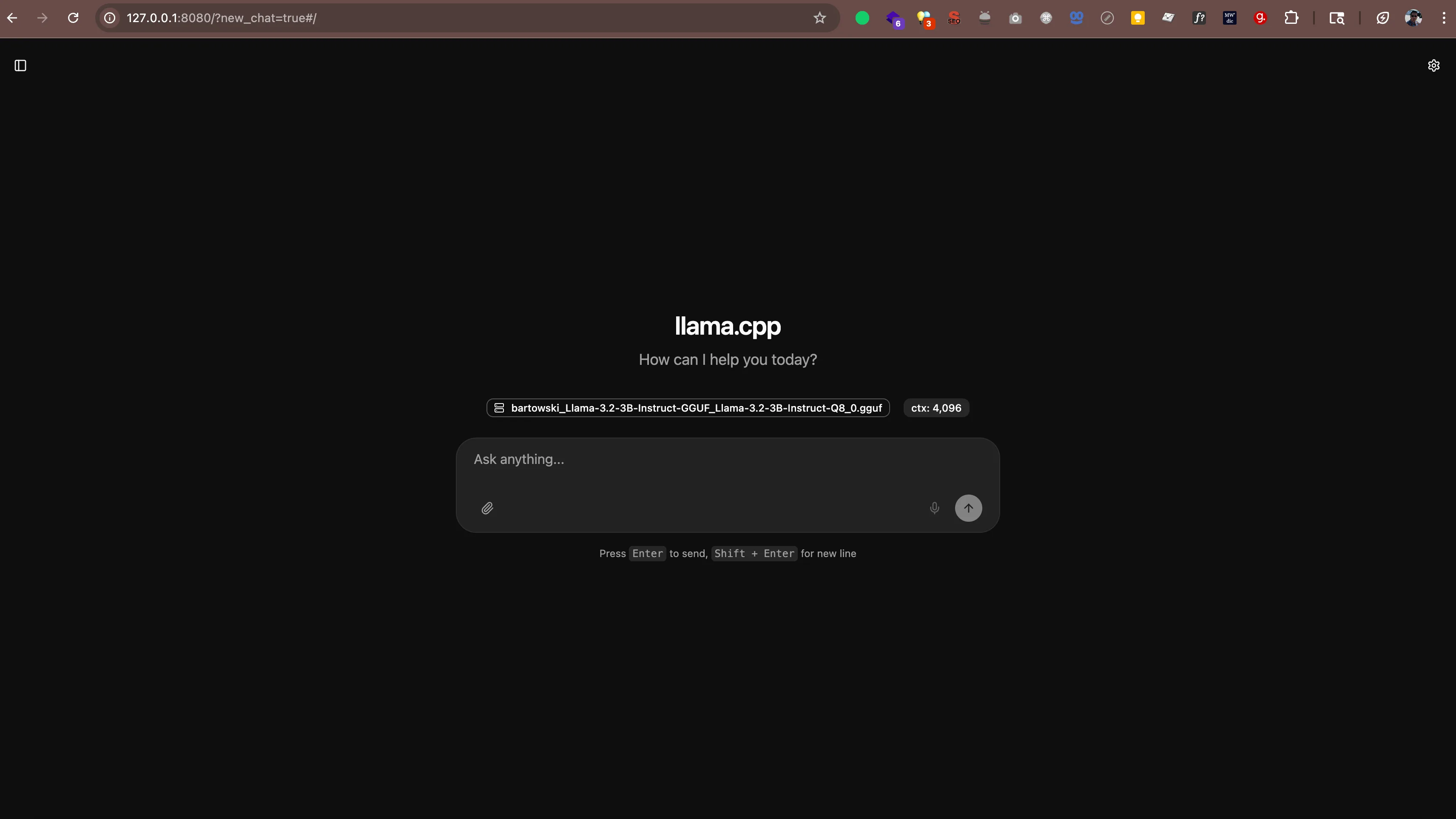
The server also works with any app that supports OpenAI's API format. This means you can use tools like:
- Continue.dev (AI coding assistant in VS Code)
- Open WebUI (a ChatGPT-like interface)
- Any other app that supports custom API endpoints
Where the models are stored
When you run these commands, models download automatically to a cache folder. By default, it's in your home directory under .cache/llama.cpp.
If you want to change where models are stored, you can set an environment variable:
# On Mac/Linux
export LLAMA_CACHE=/path/to/your/cache
# On Windows (PowerShell)
$env:LLAMA_CACHE="C:\path\to\your\cache"What about performance?
Here's what I learned about performance:
- On newer Macs (M1/M2/M3/M4): Models run surprisingly fast. The M-series chips have built-in AI acceleration.
- On Windows/Linux with a decent GPU: Also fast. If you have an NVIDIA GPU, llama.cpp will use it automatically.
- On older computers or laptops without GPUs: Still works! Just stick with smaller models (3B or 7B) and expect slower responses.
For reference, on my M4 Pro with 48GB RAM, a 3B model generates text at about 60-65 tokens per second. That's fast enough to feel like a real conversation.
llama.cpp vs Ollama vs vLLM
You might have heard of other tools like Ollama or vLLM. Here's how they compare:
Ollama
Ollama is built on top of llama.cpp. It adds a simpler interface and automatic model management, but that convenience comes with performance overhead. In my tests on an M4 Pro Mac with 48GB RAM, llama.cpp was an order of magnitude faster than Ollama running the same models.
If you want maximum performance and don't mind using the command line, stick with llama.cpp. If you prefer easier model management and can accept slightly slower speeds, Ollama works well.
vLLM
vLLM doesn't support macOS. It's Linux-only and designed for high-throughput server deployments with multiple GPUs. If you're on a Mac, it's not an option.
Bottom line
For Mac users, especially on Apple Silicon (M1/M2/M3/M4), llama.cpp is the best choice. It's the fastest option and has native Metal acceleration. Ollama is fine if you want simpler management. vLLM isn't available on Mac.
Questions you might have
Is this legal?
Yes. The models on Hugging Face are open source and free to use. Many are published by Meta (Facebook), Mistral AI, and other organizations that explicitly allow personal and commercial use.
Will this slow down my computer?
While the AI is running, it uses CPU/GPU resources. But when you close it, everything returns to normal. It's like running any other application.
Can I use this for work?
That depends on your work's policies. Since everything runs locally and your data doesn't leave your machine, it's generally safer than cloud AI. But check with your IT department first.
Do I need to be online?
Only for the initial download of models. After that, everything works completely offline.
My experience
I've been using my local AI, and I'm impressed. It's not quite as capable as GPT-5, Claude Sonnet 4.5, or Gemini 2.5, but for many tasks (writing emails, brainstorming ideas, answering questions) it's more than good enough.
What I appreciate most is the privacy aspect. My conversations stay on my machine. No data sent to external servers. No training datasets being fed somewhere. This makes it better suited for working with confidential information compared to cloud AI, though you should still follow your organization's security policies.
Is it perfect? No. Responses can sometimes be slow if I'm running a larger model. And the quality isn't quite at the level of the best cloud AIs. But for a free, private, always-available assistant? I'll take that trade-off.